रूसी शेयर बाजार गोर्बाचेव विक्टर विक्टरोविच के विकास का सांख्यिकीय विश्लेषण और पूर्वानुमान। शेयर बाज़ार की भविष्यवाणी. एक शाम की कहानी, गैर-नकद मुद्रा आपूर्ति की वृद्धि दर
संयुक्त अरब अमीरात में स्थित इस्लामिक आज़ाद विश्वविद्यालय के कंप्यूटर विज्ञान संकाय के वैज्ञानिकों ने समर्थन वेक्टर मशीनों का उपयोग करके तंत्रिका नेटवर्क प्रौद्योगिकियों, आनुवंशिक एल्गोरिदम और डेटा खनन के आधार पर स्टॉक सूचकांकों के व्यवहार की भविष्यवाणी पर एक पेपर प्रकाशित किया। हम आपके ध्यान में इस दस्तावेज़ के मुख्य विचार प्रस्तुत करते हैं।
परिचय
हाल के वर्षों में वित्तीय विश्लेषण के लोकप्रिय क्षेत्रों में से एक पिछले व्यापारिक अवधि के डेटा के आधार पर स्टॉक की कीमतों और स्टॉक सूचकांकों के व्यवहार का पूर्वानुमान लगाना है। किसी भी प्रासंगिक परिणाम को प्राप्त करने के लिए उपयुक्त उपकरण और सही एल्गोरिदम का उपयोग करना आवश्यक है।वैज्ञानिकों ने विशेष सॉफ्टवेयर विकसित करने का लक्ष्य निर्धारित किया है जो पूर्वानुमानित एल्गोरिदम और गणितीय नियमों का उपयोग करके स्टॉक सूचकांकों के व्यवहार का पूर्वानुमान उत्पन्न कर सकता है।
स्टॉक सूचकांक स्वयं अप्रत्याशित हैं क्योंकि वे न केवल आर्थिक घटनाओं पर निर्भर करते हैं, बल्कि वे दुनिया के विभिन्न हिस्सों में राजनीतिक स्थिति से भी प्रभावित होते हैं। इसलिए, ऐसी अप्रत्याशित, अरेखीय और गैर-पैरामीट्रिक समय श्रृंखला को संभालने के लिए गणितीय मॉडल विकसित करना बेहद मुश्किल है।
शेयर बाज़ार में काम करते समय दो प्रकार के विश्लेषण का उपयोग किया जाता है।
1) तकनीकी विश्लेषण
अल्पकालिक वित्तीय रणनीतियों के लिए उपयोग किया जाता है। इसका उपयोग अतीत में समान तरीकों से बदलते पैटर्न और कीमतों के आधार पर मूल्य परिवर्तन की भविष्यवाणी करने के लिए किया जाता है। एक नियम के रूप में, मूल्य चार्ट का विश्लेषण किया जाता है, जो मूल्य गतिशीलता में कुछ पैटर्न के पैटर्न को उजागर करता है। मूल्य परिवर्तन की गतिशीलता का अध्ययन करने के अलावा, तकनीकी विश्लेषण ट्रेडिंग वॉल्यूम और अन्य सांख्यिकीय डेटा पर जानकारी का उपयोग करता है।
2) मौलिक विश्लेषण
दीर्घकालिक निवेश रणनीतियों के लिए मौलिक विश्लेषण का उपयोग किया जाता है। इसमें किसी विशेष कंपनी के शेयरों की कीमत की भविष्यवाणी करने के लिए उसकी गतिविधियों के वित्तीय और उत्पादन संकेतकों के बारे में जानकारी का उपयोग करना शामिल है।
इसके अलावा, संभावित मूल्य आंदोलनों की भविष्यवाणी करते समय, वित्तीय बाजार में मौजूद खिलाड़ियों के लिए इसमें मौजूद जोखिमों को समझना आवश्यक है:
- ट्रेडिंग जोखिम- धन की वह राशि जो व्यापारी जोखिम में डालता है। उदाहरण के लिए, यदि वह एक हजार डॉलर में कोई वित्तीय परिसंपत्ति खरीदता है, तो व्यापारिक जोखिम इस राशि के बराबर होगा।
- बाजार ज़ोखिम- अन्य बातों के अलावा, वैश्विक आर्थिक घटनाओं या किसी विशिष्ट देश में घटनाओं के प्रभाव में बाजार में क्या हो सकता है जहां वित्तीय बाजार स्थित है या जिन कंपनियों के शेयरों का स्टॉक एक्सचेंज पर कारोबार होता है।
- मार्जिन जोखिम- यदि उधार ली गई धनराशि का उपयोग लेनदेन करने के लिए किया जाता है, तो मार्जिन जोखिम उत्पन्न होता है। उदाहरण के लिए, किसी ब्रोकर से उधार लिया गया पैसा अंततः वापस करना होगा, और यदि व्यापारी के पास ऐसा करने के लिए खाते में पर्याप्त धनराशि नहीं है, तो उसकी स्थिति जबरन बंद कर दी जाएगी, भले ही यह उसके द्वारा निहित न हो ट्रेडिंग रणनीति.
- तरलता जोखिम- हर वित्तीय साधन को जल्दी से "बाहर" नहीं निकाला जा सकता।
- रातोरात पोजीशन पलटने का जोखिम- व्यापारिक दिनों के बीच या कई व्यापारिक दिनों के बीच स्थिति बनाए रखने में जोखिम होता है, क्योंकि व्यापारी को यह नहीं पता होता है कि जब एक्सचेंज काम नहीं कर रहा है तो क्या होगा। शायद कोई घटना कारोबारी दिन की शुरुआत को प्रभावित करेगी, और शेयर की कीमत तुरंत इस तरह से बदल जाएगी जो निवेशक के लिए प्रतिकूल है।
- अस्थिरता का जोखिम- शेयर की कीमत कुछ निश्चित सीमाओं के भीतर उतार-चढ़ाव करती है। मूल्य में उतार-चढ़ाव की सीमा जितनी व्यापक होगी, किसी विशेष वित्तीय साधन की अस्थिरता उतनी ही अधिक होगी।
स्टॉक सूचकांकों के व्यवहार का पूर्वानुमान लगाना
स्टॉक मूल्य पूर्वानुमान समस्याओं को हल करने के लिए उपयोग किए जाने वाले लोकप्रिय उपकरणों में से एक निर्णय वृक्ष है। बदले में, डेटा एकत्र करने और उसका विश्लेषण करने का सबसे प्रभावी तरीका डेटा माइनिंग है। डेटा माइनिंग का उपयोग करने के लिए कई मॉडल हैं, जो प्राप्त जानकारी को एकत्र करने और उसका विश्लेषण करने के लिए विभिन्न तरीकों को लागू करते हैं।हमारे मामले में, शोधकर्ताओं ने CRISP-DM (डेटा माइनिंग के लिए क्रॉस-आइडेंटिटी स्टैंडर्ड प्रोसेस) मॉडल को चुना। यह पद्धति पिछली शताब्दी के मध्य नब्बे के दशक में यूरोपीय कंपनियों के एक संघ द्वारा विकसित की गई थी। मॉडल में सात मुख्य चरण शामिल हैं:
- जानकारी की खोज के लिए लक्ष्य निर्धारित करना (डेटा जिसके बारे में स्टॉक की आवश्यकता है)।
- आवश्यक डेटा ढूँढना.
- वर्गीकरण मॉडल में डेटा व्यवस्थित करना।
- मॉडल को लागू करने के लिए प्रौद्योगिकी का चयन.
- ज्ञात विधियों का उपयोग करके मॉडल मूल्यांकन।
- लक्ष्य कार्रवाई के लिए अनुशंसा उत्पन्न करने के लिए मौजूदा बाजार स्थितियों में मॉडल को लागू करना - उदाहरण के लिए, स्टॉक खरीदना या बेचना।
- प्राप्त परिणामों का मूल्यांकन।
आनुवंशिक एल्गोरिदम का उपयोग पूर्वानुमान के लिए भी किया जाता है। उनका उपयोग उन मामलों में जटिल समस्याओं को हल करने के लिए किया जाता है जहां शामिल तत्वों के बीच सटीक संबंध अज्ञात हैं और सिद्धांत रूप में मौजूद नहीं हो सकते हैं।
समस्या को औपचारिक रूप दिया गया है ताकि इसके समाधान को जीन के वेक्टर ("जीनोटाइप") के रूप में एन्कोड किया जा सके, जहां प्रत्येक जीन एक बिट, एक संख्या या किसी अन्य वस्तु का प्रतिनिधित्व कर सकता है। इसके बाद, प्रारंभिक "जनसंख्या" के कई जीनोटाइप यादृच्छिक रूप से बनाए जाते हैं, जिनका मूल्यांकन एक विशेष फिटनेस फ़ंक्शन का उपयोग करके किया जाता है। परिणामस्वरूप, प्रत्येक जीनोटाइप को एक "फिटनेस" मान दिया जाता है - यही वह है जो निर्धारित करता है कि यह समस्या को कितनी अच्छी तरह हल करता है।
किसी ट्रेडिंग रणनीति में शामिल मापदंडों को लगातार अनुकूलित करने के लिए अनुकूलन विधियों का उपयोग किया जाता है। उदाहरण के लिए, एक जीन को एक वेक्टर के रूप में दर्शाया जा सकता है, और संबंधित अनुकूलन एल्गोरिदम उस पर मध्यवर्ती पुनर्संयोजन तंत्र लागू करता है।
भविष्य के मूल्य आंदोलनों के बारे में पूर्वानुमान उत्पन्न करने का एक तरीका मशीन लर्निंग है। इस मामले में, शोधकर्ताओं ने सपोर्ट वेक्टर मशीनों का इस्तेमाल किया। शोधकर्ताओं ने NASDAQ एक्सचेंज के साथ-साथ कुछ वित्तीय उपकरणों और सूचकांकों से वित्तीय डेटा एकत्र किया। परिणामस्वरूप, NASDAQ के लिए सिस्टम द्वारा उत्पन्न भविष्यवाणियों की सटीकता 74.4%, DJIA सूचकांक के लिए 77.6% और S&P500 के लिए 76% थी।
मशीन लर्निंग के लिए निम्नलिखित सूत्रों का उपयोग किया गया:
सबसे पहले, x i (t) निर्धारित किया गया था, जहां i ∈ (1, 2,…)।
एफ = (एक्स 1, एक्स 2, ... एक्स एन) टी, कहां

उपयोग किए गए मॉडल का मूल्यांकन करने के लिए, मूल माध्य वर्ग त्रुटि (आरएमएसई, माध्य वर्ग त्रुटि का मूल) की गणना करने की विधि का उपयोग किया गया था:
बहु-वर्ग वर्गीकरण
जोखिमों को कम करने और मुनाफ़े को बढ़ाने के लिए सपोर्ट वेक्टर मशीन का उपयोग किया जाता है। इसमें डेटा को तीन श्रेणियों में वर्गीकृत करना शामिल है: सकारात्मक, नकारात्मक और तटस्थ। इससे सबसे जोखिम भरे पूर्वानुमानों की पहचान करने और उन्हें अस्वीकार करने में मदद मिलती है। ऐसा मल्टीक्लास क्लासिफायरियर बनाने के लिए, केंद्रीय क्षेत्र की चौड़ाई निर्धारित करना आवश्यक है:
टीपी: सच्चा सकारात्मक
एफपी: गलत सकारात्मक
एफएन: गलत नकारात्मक
प्रस्तावित मॉडल
जैसा कि ऊपर उल्लेख किया गया है, एकत्र किए गए डेटा में छह विशेषताएं थीं। निर्णय वृक्ष में उपयोग करने के लिए, डेटा को अलग-अलग मानों में परिवर्तित किया जाना चाहिए। ऐसा करने के लिए, आप बाज़ार के समापन मूल्य पर आधारित एक मानदंड का उपयोग कर सकते हैं। यदि वर्तमान ट्रेडिंग दिवस के दौरान ओपन, अधिकतम, न्यूनतम और अंतिम का मान पिछले विशेषता मान से अधिक हो जाता है, तो सकारात्मक मान को पिछली विशेषता के साथ प्रतिस्थापित किया जाना चाहिए। इसके विपरीत, पिछली विशेषता के स्थान पर एक नकारात्मक मान सेट किया जाता है, और यदि मान बराबर हैं, तो संबंधित विशेषता सेट की जाती है।छह विशेषताओं के लिए डेटा सेट अलग-अलग मानों में परिवर्तित होने से पहले ऐसा दिखता है:

और यहाँ यह अनुवाद के बाद है:

असतत मूल्यों का ऐसा सेट प्राप्त करने के बाद, निर्णय वृक्ष का उपयोग करके एक वर्गीकरण मॉडल बनाना आवश्यक है।
यह अध्ययन दो संभावित कार्रवाई परिदृश्यों की जांच करता है।
परिद्रश्य 1
आपको निम्नलिखित कार्य करने होंगे:- 30 दिनों के लिए ट्रेडों पर वित्तीय डेटा एकत्र करें।
- एक कारोबारी दिन के दौरान 9 बिंदुओं पर छह विशेषताओं के लिए डेटा का चयन करें।
- प्रत्येक सेट के लिए, एक मैट्रिक्स बनाएं।
- XX^T की गणना करें और आइजनवैल्यू उत्पन्न करने के लिए सपोर्ट वेक्टर मशीनें लागू करें।
- बिक्री और खरीद की औसत मात्रा की गणना।
- प्रत्येक कारोबारी दिन के औसत की गणना करें।
- पहले दिन, सातवें दिन, तीसवें दिन और मासिक औसत को अलग-अलग भार देना।
- कार्रवाई अनुशंसा उत्पन्न करने के लिए, आपको वर्तमान मूल्य की तुलना पहले, सातवें, तीसवें दिन के साथ-साथ पूरे महीने के औसत मूल्य से करनी होगी।
- यदि पूर्वानुमान परिणाम 4 ट्रेडिंग दिनों के लिए समान है, तो आपको खरीदारी करनी चाहिए; यदि तीन ट्रेडिंग दिनों के लिए मैच होता है, तो खरीदारी में 25% का जोखिम होगा, दो दिनों के लिए जोखिम 50% होगा।

इसके बाद, आर = एक्सएक्स टी की गणना की जाती है - प्रत्येक मैट्रिक्स को ट्रांसपोज़्ड संस्करण से गुणा किया जाना चाहिए। फिर समर्थन वेक्टर और उसके आइगेनवैल्यू की गणना की जाती है।
परिदृश्य 2
इस मामले में, सभी समान चरण निष्पादित किए जाते हैं, लेकिन समर्थन वेक्टर मशीन "कच्चे" डेटा पर नहीं, बल्कि ऑटोसहसंबंध के बाद प्राप्त मैट्रिक्स पर लागू होती है। प्रत्येक व्यापारिक दिन के लिए, एक ऑटोसहसंबंध मैट्रिक्स उत्पन्न होता है:
यहाँ निम्नलिखित सूत्र का उपयोग किया जाता है:

स्वत:सहसंबंध के बाद हमें एक नया मैट्रिक्स (Toeplitz मैट्रिक्स) प्राप्त होता है:

और इसके लिए सपोर्ट वेक्टर और आइजेनवैल्यू की गणना पहले ही की जा चुकी है। विभिन्न व्यापारिक दिनों के बीच माध्य से विचलन की तुलना करने के लिए, माध्य, विचरण और मानक विचलन की गणना की जाती है और एक वेक्टर में संग्रहीत किया जाता है।
निष्कर्ष
सर्वोत्तम परिणाम प्राप्त करने के लिए, शोधकर्ताओं ने सभी वर्णित तरीकों को चरण दर चरण लागू किया: मौलिक विश्लेषण से शुरू करके, आनुवंशिक एल्गोरिदम, तंत्रिका नेटवर्क, मशीन लर्निंग और समर्थन वेक्टर मशीनों का उपयोग करना।
साथ ही, स्टॉक सूचकांक मूल्यों में परिवर्तन की भविष्यवाणी में 100% सटीकता प्राप्त करना संभव नहीं था। विभिन्न वित्तीय साधनों के लिए, एक कारोबारी दिन की अवधि में सूचकांकों के व्यवहार की भविष्यवाणी करने की सटीकता काफी भिन्न होती है:

जर्मन DAX सूचकांक के लिए सबसे अच्छा परिणाम 70.8% की सटीकता था। दीर्घकालिक पूर्वानुमानों (30 दिनों से अधिक की अवधि) के लिए अधिक सटीकता प्राप्त करने के लिए, निम्नलिखित सूत्र का उपयोग किया गया था:
पीआर (v t+1 – v t > c t ), जहां c t = -(v t-ts – v t)
इस मामले में, सर्वोत्तम पूर्वानुमान सटीकता परिणाम 85.0% था।
सूचना प्रौद्योगिकी के तेजी से विकास के लिए धन्यवाद, बड़ी मात्रा में जानकारी का विश्लेषण करना, जटिल गणितीय मॉडल बनाना और कुछ ही सेकंड में बहुमानदंड अनुकूलन समस्याओं को हल करना संभव हो गया है। चक्रीय आर्थिक विकास में रुचि रखने वाले वैज्ञानिकों ने सिद्धांत विकसित करना शुरू कर दिया, यह विश्वास करते हुए कि कई आर्थिक चर में रुझानों पर नज़र रखने से तेजी और मंदी की अवधि को स्पष्ट करने और भविष्यवाणी करने में मदद मिलेगी। अध्ययन के लिए शेयर बाजार को एक वस्तु के रूप में चुना गया था। एक गणितीय मॉडल बनाने के लिए बार-बार प्रयास किए गए हैं जो स्टॉक की कीमतों में वृद्धि की भविष्यवाणी करने की समस्या को सफलतापूर्वक हल कर देगा। विशेष रूप से, "तकनीकी विश्लेषण" व्यापक हो गया है।
तकनीकी विश्लेषण(तकनीकी विश्लेषण) बाजार की गतिशीलता का अध्ययन करने के लिए तरीकों का एक सेट है, अक्सर चार्ट के माध्यम से, मूल्य आंदोलनों की भविष्य की दिशा की भविष्यवाणी करने के लिए। आज, यह विश्लेषणात्मक पद्धति सबसे लोकप्रिय में से एक है। लेकिन क्या हम उन पर विचार कर सकते हैं. क्या विश्लेषण लाभ कमाने के लिए उपयुक्त है? सबसे पहले, आइए शेयर बाजार में मूल्य निर्धारण के सिद्धांतों पर नजर डालें।
1960 के दशक से बुनियादी अवधारणाओं में से एक। गिनता निपुण बाजार अवधारणा(प्रभावी बाजार परिकल्पना, ईएमएच), जिसके अनुसार पिछली अवधि के लिए कीमतों और बिक्री की मात्रा की जानकारी सार्वजनिक रूप से उपलब्ध है। नतीजतन, पिछले उद्धरणों के विश्लेषण से जो भी डेटा निकाला जा सकता है, वह पहले ही स्टॉक मूल्य में अपना रास्ता खोज चुका है। चूँकि व्यापारी इस सार्वजनिक ज्ञान का बेहतर उपयोग करने के लिए प्रतिस्पर्धा करते हैं, वे आवश्यक रूप से कीमतों को उस स्तर तक ले जाते हैं जिस पर रिटर्न की अपेक्षित दरें पूरी तरह से जोखिम के अनुरूप होती हैं। इन स्तरों पर यह कहना असंभव है कि स्टॉक खरीदना एक अच्छा सौदा है या बुरा, यानी। वर्तमान कीमत वस्तुनिष्ठ है, जिसका अर्थ है कि आप बाज़ार से ऊपर रिटर्न प्राप्त करने की उम्मीद नहीं कर सकते। इस प्रकार, एक कुशल बाजार में, परिसंपत्ति की कीमतें उनके वास्तविक मूल्यों और उनके आचरण को दर्शाती हैं। विश्लेषण का सारा अर्थ खो जाता है।
लेकिन यह ध्यान दिया जाना चाहिए कि आज दुनिया के मौजूदा शेयर बाजारों में से किसी को भी पूरी तरह से सूचनात्मक रूप से कुशल नहीं कहा जा सकता है। इसके अलावा, आधुनिक अनुभवजन्य अनुसंधान को ध्यान में रखते हुए, हम यह निष्कर्ष निकाल सकते हैं कि एक कुशल बाजार का सिद्धांत एक स्वप्नलोक है, क्योंकि वित्तीय बाज़ारों में होने वाली वास्तविक प्रक्रियाओं को पूरी तरह से तर्कसंगत रूप से समझाने में सक्षम नहीं है।

विशेष रूप से, येल विश्वविद्यालय के प्रोफेसर रॉबर्ट शिलर ने एक घटना की खोज की जिसे बाद में उन्होंने स्टॉक परिसंपत्ति की कीमतों में अत्यधिक अस्थिरता कहा। घटना का सार उद्धरणों में बार-बार होने वाले परिवर्तनों में निहित है, जो तर्कसंगत व्याख्या को अस्वीकार करता है, अर्थात्, मूलभूत कारकों में संबंधित परिवर्तनों के साथ इस घटना की व्याख्या करने की कोई संभावना नहीं है।.
1980 के दशक के अंत में. एक ऐसा मॉडल बनाने की दिशा में पहला कदम उठाया गया, जो एक कुशल बाजार की अवधारणा के विपरीत, शेयर बाजारों के वास्तविक व्यवहार को अधिक सटीक रूप से समझाएगा। 1986 में, फिशर ब्लैक ने अपने प्रकाशन में एक नया शब्द पेश किया - "शोर व्यापार"।

« शोर व्यापारशोर पर कारोबार हो रहा है, ऐसा माना जाता है मानो शोर सूचना हो। जो लोग शोर मचाकर व्यापार करते हैं वे तब भी व्यापार करेंगे जब वस्तुनिष्ठ रूप से उन्हें ऐसा करने से बचना चाहिए। शायद उनका मानना है कि जिस शोर पर वे व्यापार करते हैं वह सूचना है। या शायद वे सिर्फ व्यापार करना पसंद करते हैं" हालाँकि एफ. ब्लैक यह नहीं दर्शाता है कि किन ऑपरेटरों को "शोर व्यापारियों" के रूप में वर्गीकृत किया जाना चाहिए, ऐसे बाजार सहभागियों का विवरण डी लॉन्ग, श्लीफ़र, समर्स और वाल्डमैन के काम में पाया जा सकता है। शोर मचाने वाले व्यापारी गलती से मानते हैं कि उनके पास भविष्य की संपत्ति की कीमतों के बारे में अनोखी जानकारी है। ऐसी जानकारी के स्रोत तकनीकी संकेतकों द्वारा दिए गए गैर-मौजूद रुझानों के बारे में गलत संकेत हो सकते हैं। विश्लेषण, अफवाहें, वित्तीय "गुरुओं" की सिफारिशें। शोर मचाने वाले व्यापारी उपलब्ध जानकारी के मूल्य को बहुत अधिक महत्व देते हैं और अनुचित रूप से बड़े जोखिम लेने को तैयार रहते हैं। आयोजित अनुभवजन्य अध्ययनों से यह भी संकेत मिलता है कि शोर व्यापारियों को मुख्य रूप से व्यक्तिगत निवेशकों को शामिल करना चाहिए, अर्थात। व्यक्तियों. इसके अलावा, यह व्यापारियों का वह समूह है जो अपने कार्यों की अतार्किकता के कारण व्यापार से व्यवस्थित नुकसान उठाते हैं। पश्चिमी शेयर बाजारों के लिए, इस घटना की अनुभवजन्य पुष्टि बार्बर और ओडिन के अध्ययन में और रूसी शेयर बाजार के संचालकों के लिए - आई.एस. के काम में पाई जा सकती है। निलोवा. शोर व्यापार का सिद्धांत आर. शिलर की घटना को समझाने में भी मदद करता है। यह व्यापारियों के तर्कहीन कार्य हैं जो अत्यधिक मूल्य अस्थिरता का कारण बनते हैं।
शेयर बाजार में मूल्य निर्धारण सिद्धांतों के क्षेत्र में आधुनिक शोध को सारांशित करते हुए, हम यह निष्कर्ष निकाल सकते हैं कि लाभ कमाने के लिए तकनीकी विश्लेषण का उपयोग अप्रभावी है। इसके अलावा, तकनीक का उपयोग करने वाले व्यापारी। विश्लेषण दोहराए जाने वाले ग्राफिक पैटर्न (अंग्रेजी पैटर्न से - मॉडल, नमूना) की पहचान करने का प्रयास करता है। अलग-अलग मूल्य पैटर्न खोजने की लालसा प्रबल है, और मानव आँख की स्पष्ट रुझान पहचानने की क्षमता अद्भुत है। हालाँकि, पहचाने गए पैटर्न बिल्कुल भी मौजूद नहीं हो सकते हैं।चार्ट 1956 तक डॉव जोन्स इंडस्ट्रियल एवरेज के लिए सिम्युलेटेड और वास्तविक डेटा दिखाता है, जो हैरी रॉबर्ट्स के शोध से लिया गया है।

चार्ट (बी) एक क्लासिक सिर और कंधे का पैटर्न है। चार्ट (ए) भी एक "विशिष्ट" बाज़ार व्यवहार पैटर्न जैसा दिखता है। दोनों में से कौन सा ग्राफ वास्तविक स्टॉक इंडेक्स मूल्यों पर आधारित है और कौन सा सिम्युलेटेड डेटा पर आधारित है? ग्राफ़ (ए) वास्तविक डेटा पर आधारित है। ग्राफ़ (बी) यादृच्छिक संख्या जनरेटर द्वारा उत्पादित मूल्यों का उपयोग करके उत्पन्न होता है। ऐसे पैटर्न की पहचान करने में समस्या जहां वास्तव में कोई मौजूद नहीं है, आवश्यक डेटा की कमी है। पिछली गतिशीलता का विश्लेषण करके, आप हमेशा उन व्यापारिक योजनाओं और तरीकों की पहचान कर सकते हैं जो लाभ प्रदान कर सकते हैं। दूसरे शब्दों में, उन पर आधारित अनंत रणनीतियों का एक सेट है। विश्लेषण। कुल जनसंख्या की कुछ रणनीतियाँ ऐतिहासिक डेटा पर सकारात्मक परिणाम प्रदर्शित करती हैं, अन्य - नकारात्मक। लेकिन भविष्य में, हम यह नहीं जान सकते कि सिस्टम का कौन सा समूह हमें लगातार लाभ कमाने की अनुमति देगा।
इसके अलावा, समय श्रृंखला में पैटर्न की उपस्थिति निर्धारित करने का एक तरीका मापना है क्रमिक सहसंबंध. उद्धरणों में क्रमिक सहसंबंध का अस्तित्व अतीत और वर्तमान स्टॉक रिटर्न के बीच एक निश्चित संबंध का संकेत दे सकता है। एक सकारात्मक क्रमिक सहसंबंध का मतलब है कि रिटर्न की सकारात्मक दरें आमतौर पर सकारात्मक दरों (दृढ़ता संपत्ति) के साथ होती हैं। नकारात्मक क्रमिक सहसंबंध का मतलब है कि रिटर्न की सकारात्मक दरें नकारात्मक दरों (प्रत्यावर्तन संपत्ति या "सुधार" संपत्ति) के साथ होती हैं। इस पद्धति को स्टॉक कोट्स पर लागू करके, केंडल और रॉबर्ट्स (1959) ने साबित किया कि किसी भी पैटर्न का पता नहीं लगाया जा सकता है।
तकनीकी विश्लेषण के साथ-साथ यह काफी व्यापक हो गया है मौलिक विश्लेषण. इसका उद्देश्य कमाई और लाभांश संभावनाओं, भविष्य की ब्याज दरों की अपेक्षाओं और फर्म के जोखिम जैसे कारकों के आधार पर स्टॉक के मूल्य का विश्लेषण करना है। लेकिन, तकनीकी विश्लेषण की तरह, यदि सभी विश्लेषक किसी कंपनी की कमाई और उद्योग की स्थिति के बारे में सार्वजनिक रूप से उपलब्ध जानकारी पर भरोसा करते हैं, तो यह उम्मीद करना मुश्किल है कि संभावनाओं के बारे में किसी एक विश्लेषक का आकलन दूसरों की तुलना में अधिक सटीक होगा। इस तरह का बाज़ार अनुसंधान कई सुविज्ञ और उदारतापूर्वक वित्त पोषित फर्मों द्वारा किया जाता है। ऐसी भयंकर प्रतिस्पर्धा को देखते हुए, ऐसा डेटा ढूंढना मुश्किल है जो अन्य विश्लेषकों के पास पहले से नहीं है। इसलिए, यदि किसी विशेष कंपनी के बारे में जानकारी सार्वजनिक रूप से उपलब्ध है, तो एक निवेशक जिस रिटर्न की उम्मीद कर सकता है वह सबसे आम दर होगी।
ऊपर वर्णित विधियों के अलावा, वे बाजार का पूर्वानुमान लगाने के लिए तंत्रिका नेटवर्क, आनुवंशिक एल्गोरिदम आदि का उपयोग करने का प्रयास कर रहे हैं। लेकिन वित्तीय बाज़ारों के संबंध में पूर्वानुमानित तरीकों का उपयोग करने का प्रयास उन्हें बदल देता है आत्म-विनाशकारी मॉडल. उदाहरण के लिए, मान लीजिए कि कोई एक तरीका बाज़ार की अंतर्निहित विकास प्रवृत्ति की भविष्यवाणी करता है। यदि सिद्धांत को व्यापक रूप से स्वीकार किया जाता है, तो कई निवेशक बढ़ती कीमतों की प्रत्याशा में तुरंत शेयर खरीदना शुरू कर देंगे। परिणामस्वरूप, विकास अनुमान से कहीं अधिक तेज़ और तेज़ होगा। या इस तथ्य के कारण विकास बिल्कुल भी नहीं हो सकता है कि एक बड़ा संस्थागत भागीदार, अत्यधिक तरलता की खोज के बाद, अपनी संपत्ति बेचना शुरू कर देता है।
भविष्य कहनेवाला मॉडल का आत्म-विनाश प्रतिस्पर्धी माहौल में उनके उपयोग के कारण उत्पन्न होता है, अर्थात् ऐसे वातावरण में जिसमें प्रत्येक एजेंट एक निश्चित तरीके से पूरे सिस्टम को प्रभावित करके अपना लाभ निकालने का प्रयास करता है। पूरे सिस्टम पर एक व्यक्तिगत एजेंट का प्रभाव महत्वपूर्ण नहीं है (एक काफी विकसित बाजार में), हालांकि, एक सुपरपोजिशन प्रभाव की उपस्थिति एक विशेष मॉडल के आत्म-विनाश को भड़काती है। वे। यदि ट्रेडिंग एल्गोरिदम पूर्वानुमानित तरीकों पर आधारित है, तो रणनीति अस्थिर हो जाती है, और लंबी अवधि में मॉडल स्व-समाप्त हो जाता है। यदि रणनीति पैरामीट्रिक और पूर्वानुमानित रूप से तटस्थ है, तो यह निर्णय लेने के लिए पूर्वानुमान का उपयोग करने वाले ट्रेडिंग सिस्टम की तुलना में प्रतिस्पर्धात्मक लाभ प्रदान करती है। लेकिन यह विचार करने योग्य है कि ऐसी रणनीतियों की खोज जो ऐसे मापदंडों को पूरा करती है, उदाहरण के लिए, लाभ/जोखिम, समान ऐतिहासिक डेटा और व्यावहारिक रूप से समान मानदंडों के आधार पर अन्य व्यापारियों और बड़ी वित्तीय कंपनियों द्वारा समान प्रणालियों की खोज के साथ-साथ होती है। इसका तात्पर्य न केवल आम तौर पर स्वीकृत बुनियादी मापदंडों पर आधारित प्रणालियों का उपयोग करने की आवश्यकता है, बल्कि विश्वसनीयता, स्थिरता, उत्तरजीविता, विषमलैंगिकता आदि जैसे संकेतकों पर भी है। तथाकथित पर आधारित व्यापारिक रणनीतियाँ विशेष रुचि रखती हैं। "अतिरिक्त सूचना आयाम". वे अन्य, आमतौर पर गतिविधि के संबंधित क्षेत्रों में दिखाई देते हैं और, विभिन्न कारणों से, शेयर बाजार में लोगों की एक विस्तृत श्रृंखला द्वारा शायद ही कभी उपयोग किया जाता है।
उपरोक्त विचार हमें निम्नलिखित निष्कर्ष निकालने की अनुमति देते हैं:
- शोर व्यापार का सिद्धांत, एक कुशल बाजार की अवधारणा के विपरीत, हमें स्टॉक परिसंपत्तियों के वास्तविक व्यवहार को अधिक सटीक रूप से समझाने की अनुमति देता है।
- व्यापारिक उपकरणों के उद्धरणों में परिवर्तन में कोई पैटर्न नहीं है, अर्थात। बाजार की भविष्यवाणी करना असंभव है.
- विशेष रूप से तकनीकी विश्लेषण में पूर्वानुमानित तरीकों का उपयोग, मध्यम अवधि में व्यापारी के अपरिहार्य विनाश की ओर ले जाता है।
- शेयर बाज़ार में सफलतापूर्वक व्यापार करने के लिए, "अतिरिक्त सूचना आयामों" के आधार पर पूर्वानुमानित तटस्थ रणनीतियों का उपयोग करना आवश्यक है।
प्रयुक्त साहित्य की सूची:
- शिलर आर. अतार्किक उत्साह. प्रिंसटन: प्रिंसटन यूनिवर्सिटी प्रेस, 2000।
- ब्लैक एफ. नॉइज़ // जर्नल ऑफ़ फ़ाइनेंस। 1986. वॉल्यूम. 41. आर. 529-543.
- डी लॉन्ग जे.बी., श्लीफ़र ए.एम., समर्स एल.एच., वाल्डमैन आर.जे. नॉइज़ ट्रेडर रिस्क इन फाइनेंशियल मार्केट्स // जर्नल ऑफ़ पॉलिटिकल इकोनॉमी। 1990. वॉल्यूम. 98. आर. 703-738.
- नाई बी.एम., ओडियन टी. ट्रेडिंग आपके धन के लिए खतरनाक है: व्यक्तिगत निवेशकों का सामान्य स्टॉक निवेश प्रदर्शन // जर्नल ऑफ फाइनेंस। 2000. वॉल्यूम. 55. क्रमांक 2. पी. 773-806.
- बार्बर बी.एम., ओडियन टी. लड़के तो लड़के ही रहेंगे: लिंग, अति आत्मविश्वास, और सामान्य स्टॉक निवेश // अर्थशास्त्र का त्रैमासिक जर्नल। 2001. वॉल्यूम. 116. आर. 261-292.
- ओडियन टी. क्या निवेशक बहुत अधिक व्यापार करते हैं? // अमेरिकी आर्थिक समीक्षा। 1999. वॉल्यूम. 89. आर. 1279-1298.
- निलोव आई. एस. शेयर बाजार में व्यापार करते समय कौन अपना पैसा खो देता है? // वित्तीय प्रबंधन। 2006. क्रमांक 4.
- निलोव आई. एस. शोर व्यापार। आधुनिक अनुभवजन्य अनुसंधान // आरसीबी। 2006. क्रमांक 24.
- हैरी रॉबर्ट्स. स्टॉक मार्केट पैटर्न और वित्तीय विश्लेषण: पद्धति संबंधी सुझाव // जर्नल ऑफ फाइनेंस। मार्च 1959. पृ. 5-6.
स्टॉक एक्सचेंज पर प्रतिभूतियों की कीमत दो कारकों से बनी होती है: कंपनी की पूंजी की वास्तविक लागत (इसकी संभावनाएं) और आपूर्ति और मांग का अनुपात। एक ओर, जारीकर्ता संगठन जितना बेहतर काम कर रहा है, उसकी प्रतिभूतियों की लाभप्रदता उतनी ही अधिक होगी और जोखिम उतना ही कम होगा, जिससे विनिमय दर में वृद्धि होगी। दूसरी ओर, एक सरल बाजार कानून लागू होता है: प्रतिभूतियों की मांग जितनी अधिक होगी, वे उतनी ही महंगी होंगी।
इन कारकों की अलग-अलग दिशाएँ हो सकती हैं। इस प्रकार, एक कंपनी समृद्ध हो सकती है, लेकिन बहुत अधिक आपूर्ति और कम मांग के कारण उसके शेयर सस्ते हो जाते हैं।
पहला कारक, जो कंपनी और उद्योग की वर्तमान और भविष्य की वित्तीय स्थिति को ध्यान में रखता है मौलिक विश्लेषणशेयर बाजार। दूसरा, जिसमें केवल प्रतिभूतियों की कीमतों के उतार-चढ़ाव का आकलन किया जाता है, का उपयोग तब किया जाता है तकनीकी विश्लेषण. ये शेयर बाज़ार पूर्वानुमान विधियाँ छोटी या लंबी अवधि में स्टॉक की कीमतों में उतार-चढ़ाव की भविष्यवाणी करती हैं।
शेयर बाज़ार का तकनीकी विश्लेषण
वे। स्टॉक मार्केट विश्लेषण 18वीं-19वीं शताब्दी (तथाकथित "जापानी कैंडलस्टिक्स") में सामने आया। अतीत में, जब निवेशकों के पास कंपनी की वित्तीय स्थिति के बारे में जानकारी तक पहुंच नहीं थी, तो उन्हें बाहरी संकेतकों (मुख्य रूप से, विनिमय दर की गतिशीलता) पर ध्यान केंद्रित करने के लिए छोड़ दिया गया था। यह विधि आपको अल्पावधि में कीमतों में महत्वपूर्ण वृद्धि और कमी की भविष्यवाणी करने की अनुमति देती है, लेकिन इसमें उन सभी कारकों को शामिल नहीं किया जाता है जो दर को प्रभावित कर सकते हैं।
विश्लेषक के पास केवल परिसंपत्ति मूल्य चार्ट होते हैं। शेयर बाज़ार के तकनीकी विश्लेषण के कार्यक्रम भी इन्हीं के आधार पर काम करते हैं। सबसे लोकप्रिय प्रोग्राम मेटास्टॉक है। कुछ ब्रोकर और प्लेटफ़ॉर्म अपना स्वयं का सॉफ़्टवेयर विकसित करते हैं।
रूस और दुनिया में शेयर बाजार का तकनीकी विश्लेषण तीन सिद्धांतों पर आधारित है:
1. वर्तमान कीमत में वे सभी कारक शामिल हैं जो इसे प्रभावित कर सकते हैं (कंपनी, उद्योग, बाजार आदि की स्थिति), जिसका अर्थ है कि व्यापारी को उनका अध्ययन करने की आवश्यकता नहीं है।
3. हर चीज़ अपने आप को दोहराती है. कीमत मनोवैज्ञानिक कारकों से प्रभावित होती है, जैसा कि सुदूर अतीत में था, और बाजार में तेजी, मंदी या तटस्थ प्रवृत्तियों का बोलबाला हो सकता है।
शेयर बाजार के मौलिक विश्लेषण की विशेषताएं
मौलिक विश्लेषण का प्रसार दो पूर्वापेक्षाओं के कारण है। पहला उनमें सटीकता की कमी है। शेयर बाज़ार विश्लेषण. उद्धरण का मूल्यांकन करते समय, एक व्यापारी हमेशा प्रवृत्ति को सही ढंग से ट्रैक नहीं करता है, और नई जारी करने वाली कंपनियों के संबंध में यह पूरी तरह से असंभव है: शेयरों में गतिशीलता नहीं होती है।
दूसरी शर्त स्टॉक एक्सचेंजों पर नए नियमों का उदय है। हाल ही में, प्रतिभूतियों के जारीकर्ताओं को वित्तीय विवरण प्रकाशित करना आवश्यक हो गया है। कुछ शेयरों के पक्ष में निर्णय लेते समय निवेशक इसी का विश्लेषण करते हैं।
निवेशक का कार्य परिसंपत्तियों की वास्तविक कीमत निर्धारित करना और भविष्य में इसकी गति की भविष्यवाणी करना है। विश्लेषक उद्योग और पूरे बाजार के संदर्भ में कंपनी की स्थिति का आकलन करता है और कम मूल्य वाली और अधिक मूल्य वाली प्रतिभूतियों की पहचान करता है।
शेयर बाज़ार में प्रतिभूतियों के व्यापार में मूल्य के संदर्भ में खरीद के लिए सबसे दिलचस्प शेयरों (सूचकांकों) की पहचान करने के लिए उद्धरणों का पूर्वानुमान लगाना शामिल है। यहां विश्लेषणात्मक तरीकों के बिना कोई काम नहीं कर सकता। सबसे दिलचस्प और उपयोगी में से एक है मौलिक विश्लेषण। लेखों की यह श्रृंखला इसी प्रकार के पूर्वानुमान के लिए समर्पित है।
शेयर बाजार का मौलिक विश्लेषण कई स्तरों पर प्रतिभूतियों का मूल्यांकन है (समष्टि आर्थिक, दिशात्मक विश्लेषण, किसी विशिष्ट कंपनी का विश्लेषण)। यह समझना बहुत महत्वपूर्ण है कि यह विधि रुझानों की जांच करती है और विशेष रूप से मध्यम और लंबी अवधि में काम करती है।
कुछ व्यापारी गलती से ऐसा मानते हैं शेयर बाज़ार का मौलिक विश्लेषणयह पूरी तरह से एक सांख्यिकीय स्नैपशॉट तक सीमित है। यानी, वे समाचार के एक अलग टुकड़े पर व्यापार करने की कोशिश करते हैं, यह मानते हुए कि ऐसा करके वे मौलिक विश्लेषण की ओर रुख कर रहे हैं। लेकिन इस तकनीक को समाचारों पर काम करने के रूप में परिभाषित किया गया है और यह केवल आंशिक रूप से मौलिक है। आगे, हम उन मुख्य स्तरों का विश्लेषण करेंगे जिनके साथ आप उद्धरणों की भविष्यवाणी कर सकते हैं।
शेयर बाजार विश्लेषण का व्यापक आर्थिक स्तर
शेयर बाज़ार का मौलिक विश्लेषण आर्थिक पूर्वानुमान से शुरू होना चाहिए। किसी विशेष कंपनी की गतिविधियाँ किसी विशेष राज्य की अर्थव्यवस्था और समग्र रूप से विश्व अर्थव्यवस्था दोनों के साथ बहुत निकटता से जुड़ी होती हैं।
सामान्य तौर पर, यदि आर्थिक स्थिति स्थिर है और विकास देखा जाता है, तो हम कह सकते हैं कि व्यक्तिगत उद्यम भी बढ़ेंगे। दूसरी ओर, यदि अर्थव्यवस्था में समस्याएं हैं, तो कंपनियों के महत्वपूर्ण विकास की संभावना नहीं है। लेकिन यह सामान्य तौर पर है. वास्तव में, यह सब उद्यम के दायरे पर निर्भर करता है। उदाहरण के लिए, आईटी कंपनियां संकट के दौरान भी विकास जारी रख सकती हैं।
राज्य की आर्थिक स्थिति का आकलन करने के लिए, वे आँकड़ों के एक सेट का उपयोग करते हैं जो सांख्यिकी कैलेंडर में प्रकाशित होते हैं। आज ऐसे बहुत सारे कैलेंडर हैं। उनमें सभी मुख्य संकेतक शामिल हैं जो हमें अर्थव्यवस्था में मामलों की स्थिति का आकलन करने और उचित निष्कर्ष निकालने की अनुमति देते हैं।
केंद्रीय बैंकों द्वारा अपनाई गई मौद्रिक नीतियों का शेयर बाजार के उद्धरणों पर बहुत प्रभाव पड़ता है। अपने अगले लेखों में, हम विशिष्ट उदाहरणों के साथ मूल्य आंदोलनों पर "मात्रात्मक सहजता" नामक कार्यक्रमों के प्रभाव को प्रदर्शित करेंगे।
विश्लेषण प्रक्रिया के दौरान ध्यान देने योग्य मुख्य क्षेत्र हैं:
- सकल घरेलू उत्पाद की गतिशीलता;
- रोजगार संकेतक;
- व्यावसायिक गतिविधि की गतिशीलता;
- उपभोक्ता मांग;
- केंद्रीय बैंकों के निर्णय.
ये सभी संकेतक आम तौर पर अलग-अलग राज्यों की अर्थव्यवस्था की स्थिति को दर्शाते हैं। सकल घरेलू उत्पाद की वृद्धि दर में वृद्धि यह दर्शाती है कि अर्थव्यवस्था का विकास जारी है। और यह स्टॉक के मूल्य में भविष्य में वृद्धि का संकेत दे सकता है।
शेयर बाज़ार की दिशाओं का विश्लेषण
पूर्वानुमान उद्धरण जारी रखने के लिए, विश्लेषण की ओर मुड़ना और अर्थव्यवस्था में आशाजनक दिशाओं की खोज करना आवश्यक है जो भविष्य में विकसित होंगी। यह शेयर बाज़ार का औसत मूल्यांकन स्तर है.
एक तरफ तो ऐसा काम मुश्किल लगता है. लेकिन वास्तव में, यहां कोई समस्या नहीं होनी चाहिए यदि व्यापारी आवश्यक जानकारी पा सके और उसका विश्लेषण करने का उचित प्रयास करे।
- आर्थिक विकास की अवधि के दौरान, अधिकांश क्षेत्र समृद्ध होंगे। यह कच्चे माल के साथ काम करने वाली कंपनियों और वस्तुओं और सेवाओं के उत्पादन के साथ-साथ विभिन्न विकासों में शामिल उद्यमों दोनों पर लागू होता है।
- मंदी या ठहराव की अवधि के दौरान, विपरीत तस्वीर देखी जा सकती है - व्यावसायिक गतिविधि कम हो जाती है। परिणामस्वरूप, अर्थव्यवस्था के कई क्षेत्रों में नकारात्मक गतिशीलता दिखाई दे रही है। उदाहरण के लिए, अर्थव्यवस्था में वैश्विक समस्याओं की पृष्ठभूमि में, कच्चे माल क्षेत्र को काफी नुकसान हो रहा है (चूंकि आर्थिक गतिविधि में कमी से कच्चे माल की खपत में कमी आती है)।
विभिन्न स्टॉक एक्सचेंज सूचकांक रुझानों का विश्लेषण करने में सहायता प्रदान करते हैं। उदाहरण के लिए, डॉव जोन्स इंडस्ट्रियल एवरेज अमेरिकी औद्योगिक क्षेत्र की स्थिति को दर्शाता है। डॉव जोन्स ट्रांसपोर्टेशन औसत परिवहन क्षेत्र में गतिशीलता को दर्शाता है। यदि आप इन दिशाओं में स्टॉक खरीदने की योजना बना रहे हैं, तो इन सूचकांकों के उद्धरणों का विश्लेषण करके, आप सामान्य रुझान देख सकते हैं।
शेयर बाजार कंपनियों का मौलिक विश्लेषण
 यह शेयर बाज़ार के मौलिक विश्लेषण का तीसरा स्तर है। यहां व्यापारी को भविष्य में ऊंची कीमत पर बेचने के लिए उन्हें न्यूनतम संभव लागत पर खरीदना होगा।
यह शेयर बाज़ार के मौलिक विश्लेषण का तीसरा स्तर है। यहां व्यापारी को भविष्य में ऊंची कीमत पर बेचने के लिए उन्हें न्यूनतम संभव लागत पर खरीदना होगा।
इस प्रयोजन के लिए, निम्नलिखित संकेतकों का उपयोग किया जा सकता है:
- विभिन्न संगठनों से रेटिंग;
- विश्लेषक सिफ़ारिशें;
- कंपनी समाचार (विलय, अधिग्रहण, पूंजीकरण);
- शेयरों का मुद्दा या पुनर्खरीद;
- सरकारी आदेश प्राप्त हो रहे हैं।
कंपनी की खबरें शेयर बाजार के उतार-चढ़ाव को भी प्रभावित कर सकती हैं। उदाहरण के लिए, यदि एक कंपनी दूसरे को अवशोषित करती है, तो पहला स्टॉक गिर जाएगा (यह अतिरिक्त वित्तीय लागतों के कारण है)। साथ ही, खरीदी गई कंपनी का शेयर बाजार में मूल्य बढ़ सकता है (क्योंकि इसमें वित्तीय निवेश की उम्मीद है)।
नए शेयरों का जारी होना अतिरिक्त निवेश के आकर्षण का संकेत देता है। यह खरीदारों के लिए अच्छा संकेत है. यही बात अपने शेयरों की पुनर्खरीद करने वाली कंपनियों पर भी लागू होती है।
अंत में, यदि किसी फर्म को सरकारी आदेश प्राप्त होता है, तो उसके शेयरों की कीमत में भी वृद्धि हो सकती है। तथ्य यह है कि ऐसे ऑर्डरों की मात्रा आमतौर पर बहुत महत्वपूर्ण होती है। नतीजतन, कंपनी अच्छा मुनाफा कमाएगी और संभवतः अपनी क्षमता का विस्तार करेगी। ये सारी जानकारी बाद में अलग से आती है.
सभी तीन स्तरों का विश्लेषण करके, शेयर बाजार के मौलिक विश्लेषण की खोज करके, एक व्यापारी यह समझने में सक्षम होगा कि किसी विशेष संपत्ति के लिए क्या संभावनाएं हैं। ऐसी जानकारी से वह बुद्धिमानीपूर्ण निर्णय लेने में सक्षम होगा।
यदि आपको कोई त्रुटि मिलती है, तो कृपया पाठ के एक टुकड़े को हाइलाइट करें और क्लिक करें Ctrl+Enter.
स्टॉक मार्केट पूर्वानुमान उन डेटा वैज्ञानिकों के लिए एक आकर्षक "दार्शनिक पत्थर" है जो कार्य से कम भौतिक लाभ की इच्छा से प्रेरित होते हैं। बाजार की रोजाना की तेजी और गिरावट यही बताती है ऐसे पैटर्न होने चाहिए जिन्हें हम या हमारे मॉडल सीख सकेंबिजनेस डिग्री वाले उन सभी व्यापारियों को हराने के लिए।
जब मैंने समय श्रृंखला पूर्वानुमान के लिए एडिटिव मॉडल का उपयोग करना शुरू किया, तो मैंने स्टॉक मार्केट एमुलेटर पर सिम्युलेटेड (नकली) स्टॉक के साथ विधि का परीक्षण किया। अनिवार्य रूप से, मैं उन अन्य दुर्भाग्यशाली लोगों में शामिल हो गया जो बाजार में हर दिन असफल होते हैं। हालाँकि, इस प्रक्रिया में मैंने पायथन के बारे में बहुत कुछ सीखा, जिसमें शामिल है ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग, डेटा हेरफेर, मॉडल निर्माण और विज़ुअलाइज़ेशन. इससे यह भी पता चला कि आपको एक भी पैसा खोए बिना हर दिन बाजार में खेलने पर भरोसा क्यों नहीं करना चाहिए (मैं केवल इतना कह सकता हूं कि आपको लंबी अवधि के लिए खेलने की जरूरत है)!
एक दिन बनाम 30 साल: आप अपना पैसा किसमें निवेश करेंगे?
किसी भी कार्य में, न केवल डेटा विज्ञान में, यदि आप वह हासिल नहीं कर पाते जो आप चाहते थे, तो तीन विकल्प हैं:
- परिणामों को बदलें ताकि वे अनुकूल प्रकाश में दिखाई दें;
- परिणाम छुपाएं - विफलता पर किसी का ध्यान नहीं जाएगा;
- सभी को परिणाम और विधियाँ दिखाएँ ताकि लोग कुछ सीख सकें और संभवतः सुधार का सुझाव दे सकें।
जबकि तीसरा विकल्प व्यक्तिगत और सामाजिक स्तर पर सर्वोत्तम विकल्प है, इसके लिए सबसे अधिक साहस की आवश्यकता होती है। आख़िरकार, मैं विशेष रूप से उन विशेष मामलों को प्रदर्शित कर सकता हूँ जब मेरा मॉडल लाभ कमाता है। या मैं दिखावा कर सकता हूं कि मैंने दर्जनों घंटे काम नहीं किया और इसे यूं ही फेंक दिया। कितनी बेवकूफी! दरअसल, बार-बार असफल होने और सैकड़ों गलतियाँ करने के बाद ही हम आगे बढ़ते हैं। इसके अलावा, इतने जटिल कार्य के लिए लिखा गया पायथन कोड व्यर्थ नहीं लिखा जा सकता है!
यह पोस्ट स्टॉकर की क्षमताओं का दस्तावेजीकरण करती है, जो एक बाजार पूर्वानुमान उपकरण है जिसे मैंने पायथन में विकसित किया है। मैंने दिखाया है कि विश्लेषण के लिए स्टॉकर का उपयोग कैसे करें, और जो लोग इसे स्वयं आज़माना चाहते हैं या परियोजना में योगदान देना चाहते हैं, उनके लिए पूरा कोड GitHub पर उपलब्ध है।
पूर्वानुमान के लिए स्टॉकर
स्टॉकर बाज़ार पूर्वानुमान के लिए एक पायथन टूल है। एक बार आवश्यक लाइब्रेरी स्थापित हो जाने के बाद (दस्तावेज़ीकरण देखें), आप ज्यूपिटर नोटबुक को स्क्रिप्ट के समान फ़ोल्डर में चला सकते हैं और स्टॉकर क्लास आयात कर सकते हैं:
स्टॉकर से आयात स्टॉकर
कक्षा अब ज्यूपिटर सत्र के लिए उपलब्ध है। आइए स्टॉकर क्लास का एक ऑब्जेक्ट बनाएं, इसे किसी भी वैध टिकर से पास करें, उदाहरण के लिए, 'AMZN' (प्रोग्राम आउटपुट बोल्ड में है):
अमेज़ॅन = स्टॉकर ("AMZN") AMZN स्टॉकर प्रारंभ किया गया। डेटा में 1997-05-16 से 2018-01-18 तक शामिल है।
अब हमारे पास अनुसंधान के लिए 20 वर्षों का दैनिक अमेज़न स्टॉक डेटा उपलब्ध है! स्टॉकर क्वांडल वित्तीय पुस्तकालय पर बनाया गया है और इसमें आपके उपयोग के लिए 3,000 से अधिक स्टॉक मूल्य शामिल हैं। आइए प्लॉट_स्टॉक विधि को कॉल करके एक सरल स्टॉक चार्ट बनाएं:
Amazon.plot_stock() अधिकतम समायोजन 2018-01-12 को बंद = 1305.20। न्यूनतम समायोजन 1997-05-22 को बंद = 1.40। वर्तमान समायोजन बंद करें = 1293.32.

स्टॉकर का उपयोग सामान्य रुझानों और पैटर्न का पता लगाने और उनका विश्लेषण करने के लिए किया जाता है, लेकिन अभी हम भविष्य की कीमतों की भविष्यवाणी करने पर ध्यान केंद्रित करेंगे। स्टॉकर में भविष्यवाणियाँ का उपयोग करके की जाती हैं, जो समय श्रृंखला को विभिन्न समय के पैमाने (दैनिक, साप्ताहिक और मासिक) पर प्रवृत्ति और मौसमी परिवर्तनों के संयोजन के रूप में मानता है। स्टॉकर एडिटिव मॉडलिंग के लिए फेसबुक द्वारा विकसित "भविष्यवाणी" पैकेज का उपयोग करता है। स्टॉकर में मॉडल निर्माण और पूर्वानुमान एक पंक्ति में किया जा सकता है:
# आने वाले दिनों की भविष्यवाणी करें मॉडल, मॉडल_डेटा = amazon.create_prophet_model(days=90) 2018-04-18 को अनुमानित कीमत = $1336.98
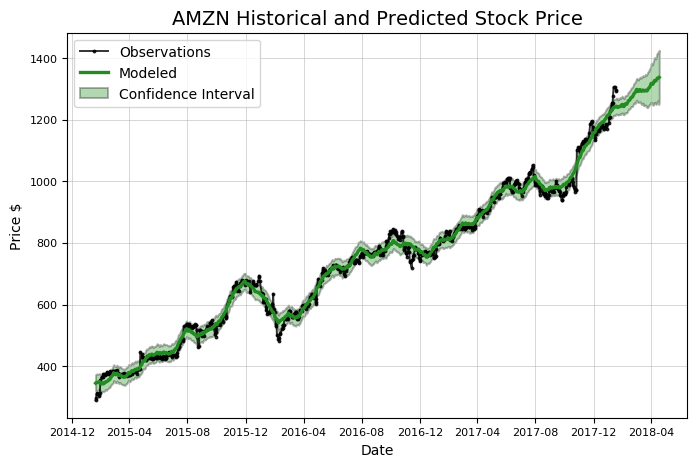
ध्यान दें कि पूर्वानुमान (हरी रेखा) में एक विश्वास अंतराल होता है। यह अपनी भविष्यवाणी में मॉडल की "अनिश्चितता" को दर्शाता है। इस मामले में, विश्वास अंतराल की चौड़ाई 80% के विश्वास स्तर के साथ निर्धारित की जाती है। कॉन्फिडेंस इंटरवल वह है जो किसी अज्ञात पैरामीटर को दी गई विश्वसनीयता के साथ कवर करता है। समय के साथ इसका विस्तार होता है क्योंकि अनुमान में अधिक अनिश्चितता होती है क्योंकि यह उपलब्ध आंकड़ों से दूर जाता है। हर बार जब आप पूर्वानुमान लगाते हैं, तो आपको इस आत्मविश्वास अंतराल को शामिल करना चाहिए। जबकि अधिकांश लोग सरल संख्यात्मक उत्तर चाहते हैं, पूर्वानुमान दर्शाता है कि हम एक अनिश्चित दुनिया में रहते हैं!
भविष्यवाणी करना आसान है:बस एक संख्या चुनें और यह भविष्य के बारे में एक अनुमान है (मैं गलत हो सकता हूं, लेकिन वॉल स्ट्रीट के लोग यही करते हैं)। लेकिन इतना पर्याप्त नहीं है। किसी मॉडल पर भरोसा करने के लिए, आपको उसकी सटीकता का मूल्यांकन करने की आवश्यकता है। स्टॉकर में ऐसा करने के लिए कई विधियाँ हैं।
पूर्वानुमानों का मूल्यांकन
भविष्यवाणियों की सटीकता की गणना करने के लिए, हमें प्रशिक्षण और परीक्षण डेटासेट की आवश्यकता है। परीक्षण सेट के लिए, हमें उत्तर जानने की आवश्यकता है - शेयरों की वास्तविक कीमत, इसलिए हम पिछले वर्ष (हमारे मामले में 2017) के मूल्य डेटा का उपयोग करेंगे। प्रशिक्षण के दौरान, हम मॉडल को परीक्षण सेट की प्रतिक्रियाओं को देखने की अनुमति नहीं देंगे, इसलिए हम पिछले तीन वर्षों (2014-2016) के अवलोकनों का उपयोग करते हैं। पर्यवेक्षित शिक्षण का मुख्य विचार यह है कि मॉडल प्रशिक्षण सेट से डेटा में पैटर्न और संबंधों को सीखता है, और फिर जानता है कि उन्हें परीक्षण सेट पर सही ढंग से कैसे पुन: पेश किया जाए।
सटीकता को मापने के लिए, अनुमानित और वास्तविक मूल्यों के आधार पर निम्नलिखित मीट्रिक की गणना की जाती है:
- परीक्षण और प्रशिक्षण सेट पर डॉलर में औसत संख्यात्मक त्रुटि;
- उस समय का प्रतिशत जब हमने मूल्य परिवर्तन की दिशा का सही अनुमान लगाया;
- उस समय का प्रतिशत जब वास्तविक कीमत अनुमानित 80% विश्वास अंतराल के भीतर गिर गई।
सभी गणनाएँ स्टॉकर द्वारा सुखद दृश्य समर्थन के साथ स्वचालित रूप से की जाती हैं:
Amazon.evaluate_prediction() पूर्वानुमान सीमा: 2017-01-18 से 2018-01-18 तक। 2018-01-17 को अनुमानित कीमत = $814.77। 2018-01-17 को वास्तविक कीमत = $1295.00. प्रशिक्षण डेटा पर औसत पूर्ण त्रुटि = $18.21। परीक्षण डेटा पर औसत निरपेक्ष त्रुटि = $183.86। जब मॉडल ने वृद्धि की भविष्यवाणी की, तो कीमत में 57.66% की वृद्धि हुई। जब मॉडल ने कमी की भविष्यवाणी की, तो कीमत में 44.64% की कमी आई। वास्तविक मूल्य समय के 20.00% 80% विश्वास अंतराल के भीतर था।

यह एक भयानक आँकड़ा है! आप हर बार एक सिक्का भी उछाल सकते हैं।यदि हमें इन परिणामों का उपयोग अपने निवेश को निर्देशित करने के लिए करना है, तो हमारे लिए लॉटरी टिकटों में निवेश करना अधिक बुद्धिमान होगा। हालाँकि, आइए अभी मॉडल को न छोड़ें। प्रारंभ में इसके काफी खराब होने की उम्मीद है क्योंकि यह कुछ डिफ़ॉल्ट सेटिंग्स (जिन्हें हाइपरपैरामीटर कहा जाता है) का उपयोग करता है।
यदि हमारे शुरुआती प्रयास असफल होते हैं, तो हम मॉडल को बेहतर प्रदर्शन करने के लिए इन लीवर और बटन को दबा सकते हैं। ऐसे कई पैरामीटर हैं जिन्हें आप पैगंबर में कॉन्फ़िगर कर सकते हैं, सबसे महत्वपूर्ण है चेंजपॉइंट पूर्व स्केल। यह वज़न के एक सेट के लिए ज़िम्मेदार है जो ट्रेंड रिवर्सल और उतार-चढ़ाव पर लागू होता है।
नियंत्रण बिंदुओं के चयन को कॉन्फ़िगर करना
परिवर्तन बिंदु- ये वे स्थान हैं जहां समय श्रृंखला महत्वपूर्ण रूप से मूल्य परिवर्तन की दिशा या दर को बदल देती है (धीरे-धीरे बढ़ने से लेकर तेजी से बढ़ने तक या इसके विपरीत)। वजन वितरण पैमाने का कारकनियंत्रण बिंदुओं के लिए (परिवर्तन बिंदु पूर्व पैमाना) स्टॉक मूल्य में परिवर्तन के बिंदुओं पर "भुगतान किए गए ध्यान" की मात्रा को दर्शाता है। इसका उपयोग मॉडल अंडरफिटिंग और ओवरफिटिंग (जिसे बायस-वेरिएंस ट्रेडिंगऑफ़ के रूप में भी जाना जाता है) को नियंत्रित करने के लिए किया जाता है।
सीधे शब्दों में कहें तो, अनुपात जितना अधिक होगा, उतने अधिक नियंत्रण बिंदुओं को ध्यान में रखा जाएगा और अधिक लचीला फिट हासिल किया जाएगा। इससे ओवरफिटिंग हो सकती है क्योंकि मॉडल प्रशिक्षण डेटा से मजबूती से बंध जाता है और सामान्यीकरण करने की क्षमता खो देता है। इस मान को कम करने से लचीलापन कम हो जाता है और विपरीत समस्या उत्पन्न होती है - कम सीखना।
इस मामले में, मॉडल प्रशिक्षण डेटा की पर्याप्त "सावधानीपूर्वक" निगरानी नहीं करता है और मुख्य पैटर्न की पहचान नहीं करता है। इस पैरामीटर को सही ढंग से कैसे चुनें यह एक सैद्धांतिक प्रश्न के बजाय एक व्यावहारिक प्रश्न है, और यहां हम अनुभवजन्य परिणामों पर भरोसा करेंगे। स्टॉकर वर्ग में उचित मूल्य का चयन करने के लिए दो अलग-अलग तरीके हैं: दृश्य और मात्रात्मक। आइए दृश्य विधि से शुरू करें।
# चेंजप्वाइंट प्रायर amazon.changepoint_prior_analyse(changepoint_priors=) का मूल्यांकन करने के लिए चेंजप्वाइंट की सूची है

यहां हम तीन साल के डेटा पर प्रशिक्षण लेते हैं और फिर अगले छह महीनों के लिए पूर्वानुमान दिखाते हैं। हम वर्तमान में मात्रात्मक रूप से भविष्यवाणियों का मूल्यांकन नहीं कर रहे हैं, बल्कि केवल नियंत्रण बिंदु वितरण की भूमिका को समझने की कोशिश कर रहे हैं। यह ग्राफ अंडर- और ओवरफिटिंग की समस्या को पूरी तरह से प्रदर्शित करता है!
न्यूनतम मूल्य पर पूर्व पैमाना(नीली रेखा) मान प्रशिक्षण डेटा (काली रेखा) के साथ पर्याप्त रूप से ओवरलैप नहीं होते हैं। ऐसा प्रतीत होता है कि वे अपना जीवन स्वयं जी रहे हैं, सच्चे डेटा की बढ़ती प्रवृत्ति के थोड़ा ही करीब। ख़िलाफ़, उच्चतम पूर्व (पीली रेखा) मॉडल को प्रशिक्षण अवलोकनों के करीब लाती है. डिफ़ॉल्ट मान 0.05 है, जो दो चरम सीमाओं के बीच कहीं है।
विभिन्न पैमाने के कारकों के लिए अनिश्चितता (छायांकित अंतराल) में अंतर पर भी ध्यान दें:
- सबसे छोटा पूर्व प्रशिक्षण डेटा में सबसे बड़ी अनिश्चितता और परीक्षण सेट में सबसे छोटा देता है।
- इसके विपरीत, उच्चतम पूर्व पैमाने पर प्रशिक्षण में सबसे कम अनिश्चितता होती है और परीक्षण में सबसे अधिक अनिश्चितता होती है।
पूर्व जितना अधिक होगा, मान उतने ही सटीक रूप से मेल खाते हैं, क्योंकि यह प्रत्येक चरण की "अधिक बारीकी से" निगरानी करता है। हालाँकि, जब परीक्षण डेटा की बात आती है, तो मॉडल वास्तविक मूल्यों के संदर्भ के बिना जल्दी से खो जाता है। क्योंकि बाज़ार अस्थिर है, एक ऐसे मॉडल की आवश्यकता है जो डिफ़ॉल्ट से अधिक लचीला हो ताकि वह यथासंभव अधिक से अधिक पैटर्न को संभाल सके।
अब जब हमें पूर्व के प्रभाव का अंदाजा हो गया है, तो हम प्रशिक्षण और परीक्षण सेट का उपयोग करके विभिन्न मूल्यों को माप सकते हैं:
Amazon.changepoint_prior_validation(start_date='2016-01-04', End_date='2017-01-03', Changepoint_priors=) मान्यता सीमा 2016-01-04 से 2017-01-03 तक। सीपीएस ट्रेन_ईआरआर ट्रेन_रेंज टेस्ट_एआरआर टेस्ट_रेंज 0.001 44.507495 152.673436 149.443609 153.341861 0.050 11.207666 35.840138 151.735924 141.033870 0.100 10 .717128 34.537544 153.260198 166.390896 0.200 9.653979 31.735506 129.227310 342.205583
हमें सावधान रहना चाहिए - सत्यापन डेटा परीक्षण सेट के समान नहीं होना चाहिए। यदि ऐसा होता, तो हम एक ऐसा मॉडल बनाते जो परीक्षण डेटा के लिए बेहतर "प्रशिक्षित" होता, जिससे ओवरफिटिंग होती और वास्तविक दुनिया में प्रदर्शन करने में विफलता होती। कुल मिलाकर, जैसा कि आमतौर पर किया जाता है, तीन सेटों का उपयोग किया जाता है: प्रशिक्षण के लिए (2013-2015), सत्यापन के लिए (2016) और एक परीक्षण सेट (2017)।
हमने चार संकेतकों के साथ चार पूर्ववर्तियों का मूल्यांकन किया:
- सीखने में त्रुटि;
- प्रशिक्षण आत्मविश्वास अंतराल;
- परीक्षण त्रुटि;
- विश्वास अंतराल का परीक्षण, डॉलर में सभी मूल्य।
ग्राफ़ दिखाता है कि पूर्व जितना अधिक होगा, प्रशिक्षण त्रुटि उतनी ही कम होगी और प्रशिक्षण डेटा पर अनिश्चितता कम होगी। यह देखा जा सकता है कि पूर्व स्तर को बढ़ाने से परीक्षण त्रुटि कम हो जाती है, इस अंतर्ज्ञान को मजबूत करते हुए कि डेटा के करीब पहुंचना बाजार के लिए एक अच्छा विचार है। परीक्षण सेट में अधिक सटीकता के बदले में, हमें पूर्व में वृद्धि के साथ परीक्षण डेटा में अनिश्चितता की एक बड़ी श्रृंखला मिलती है।
स्टॉकर सत्यापन जांच दो ग्राफ़ तैयार करती है जो इन विचारों को दर्शाते हैं:


चूंकि उच्चतम पूर्व मूल्य ने सबसे कम परीक्षण त्रुटि उत्पन्न की, इसलिए परिणामों को बेहतर बनाने के प्रयास के लिए पूर्व पैमाने को और भी बढ़ाया जाना चाहिए। सत्यापन विधि में अतिरिक्त पैरामीटर पास करके खोज को परिष्कृत किया जा सकता है:
# समान सत्यापन सीमा पर अधिक चेंजपॉइंट प्रीअर्स का परीक्षण करें amazon.changepoint_prior_validation(start_date='2016-01-04', End_date='2017-01-03', Changepoint_priors=) 
परीक्षण सेट त्रुटि को पूर्व = 0.5 पर न्यूनतम किया गया है। आइए स्टॉकर ऑब्जेक्ट विशेषता को तदनुसार सेट करें:
Amazon.changepoint_prior_scale = 0.5
अन्य परिवर्तनशील मॉडल सेटिंग्स हैं। उदाहरण के लिए, जो पैटर्न देखने की उम्मीद है, या प्रशिक्षण डेटा में उपयोग किए गए वर्षों की संख्या। सर्वोत्तम संयोजन खोजने के लिए उपरोक्त प्रक्रिया को कई अलग-अलग मानों के साथ दोहराने की आवश्यकता होती है। प्रयोग करने के लिए स्वतंत्र महसूस करें!
बेहतर मॉडल का मूल्यांकन
अब जब हमारा मॉडल अनुकूलित हो गया है, तो आइए इसका फिर से मूल्यांकन करें:
Amazon.evaluate_prediction() पूर्वानुमान सीमा: 2017-01-18 से 2018-01-18 तक। 2018-01-17 को अनुमानित कीमत = $1164.10। 2018-01-17 को वास्तविक कीमत = $1295.00. प्रशिक्षण डेटा पर औसत पूर्ण त्रुटि = $10.22। परीक्षण डेटा पर औसत निरपेक्ष त्रुटि = $101.19। जब मॉडल ने वृद्धि की भविष्यवाणी की, तो कीमत में 57.99% की वृद्धि हुई। जब मॉडल ने गिरावट की भविष्यवाणी की, तो कीमत में 46.25% की कमी आई। वास्तविक मूल्य 95.20% समय 80% विश्वास अंतराल के भीतर था।

बहुत बेहतर लग रहा है! यह मॉडल अनुकूलन के महत्व को दर्शाता है। डिफ़ॉल्ट मानों का उपयोग करने से उचित प्रथम सन्निकटन मिलता है। लेकिन हमें यह सुनिश्चित करने की ज़रूरत है कि सही सेटिंग्स का उपयोग किया जाता है, जैसे हम बैलेंस और फ़ेड (पुराने उदाहरण के लिए खेद है) को समायोजित करके स्टीरियो की ध्वनि को अनुकूलित करने का प्रयास करते हैं।
"हम बाज़ार में प्रवेश कर रहे हैं"
पूर्वानुमान लगाना निश्चित रूप से एक मज़ेदार गतिविधि है। लेकिन असली खुशी यह देखने में है कि ये पूर्वानुमान वास्तविक बाजार में कैसे काम करेंगे। मूल्यांकन_भविष्यवाणी पद्धति का उपयोग करके, हम मूल्यांकन अवधि के दौरान अपने मॉडल का उपयोग करके शेयर बाजार में "खेल" सकते हैं। हम वर्णित रणनीति का उपयोग करेंगे और एक साधारण खरीद और पकड़ो रणनीति के बराबरपूरी अवधि के दौरान.
हमारी रणनीति के नियम सरल हैं:
- हर दिन जब मॉडल भविष्यवाणी करता है कि स्टॉक बढ़ेगा, तो हम दिन की शुरुआत में शेयर खरीदते हैं और दिन के अंत में बेचते हैं। जब कीमत गिरने की भविष्यवाणी की जाती है, तो हम शेयर नहीं खरीदते हैं।
- यदि हम शेयर खरीदते हैं और दिन के दौरान कीमतें बढ़ती हैं, तो हम अपने पास मौजूद शेयरों की संख्या के गुणकों में लाभ कमाते हैं।
- यदि हम शेयर खरीदते हैं और कीमतें कम हो जाती हैं, तो हमें शेयरों की संख्या के गुणकों में नुकसान होता है।
हम इस रणनीति को पूरी मूल्यांकन अवधि के लिए हर दिन लागू करेंगे, जो इस मामले में 2017 का पूरा वर्ष है। खेलने के लिए, आपको शेयरों की संख्या को मेथड कॉल में पास करना होगा। स्टॉकर संख्याओं और ग्राफ़ में रणनीति खेलने की प्रक्रिया दिखाएगा:
# आगे बढ़ते हुए amazon.evaluate_prediction(nshares=1000) आपने 1000 शेयरों के साथ 2017-01-18 से 2018-01-18 तक AMZN में शेयर बाजार खेला। जब मॉडल ने वृद्धि की भविष्यवाणी की, तो कीमत में 57.99% की वृद्धि हुई। जब मॉडल ने गिरावट की भविष्यवाणी की, तो कीमत में 46.25% की कमी आई। पैगम्बर मॉडल का उपयोग करके कुल लाभ = $299580.00। खरीदें और रखें रणनीति लाभ = $487520.00। शेयर बाज़ार में खेलने के लिए धन्यवाद!

हमने एक मूल्यवान सबक सीखा: खरीदें और रखें!इस तथ्य के बावजूद कि हम अपनी रणनीति के अनुसार खेलकर एक महत्वपूर्ण राशि अर्जित करने में कामयाब रहे, केवल निवेश करना और शेयरों को बनाए रखना बेहतर है।
आइए यह देखने के लिए अन्य परीक्षण अवधियों का प्रयास करें कि क्या ऐसे मामले हैं जहां हमारी मॉडल रणनीति खरीद और होल्ड पद्धति से बेहतर प्रदर्शन करती है। वर्णित दृष्टिकोण काफी रूढ़िवादी है क्योंकि जब बाजार में गिरावट का अनुमान होता है तो हम नहीं खेलते हैं। इस तरह, जब स्टॉक गिरना शुरू होता है, तो यह खरीदो और पकड़ो की रणनीति से बेहतर काम कर सकता है.

केवल नकली पैसे से खेलें!
मुझे पता था कि हमारा मॉडल यह कर सकता है! हालाँकि, इसने बाज़ार को तभी मात दी जब हमारे पास परीक्षण अवधि चुनने का विकल्प था।
भविष्य के लिए पूर्वानुमान
अब जब हमारे पास एक अच्छा मॉडल है, तो हम भविष्यवाणी_फ्यूचर() विधि का उपयोग करके भविष्य के बारे में भविष्यवाणी कर सकते हैं:
Amazon.predict_future(दिन=10) amazon.predict_future(दिन=100)  10 दिन का पूर्वानुमान
10 दिन का पूर्वानुमान  100 दिन का पूर्वानुमान
100 दिन का पूर्वानुमान 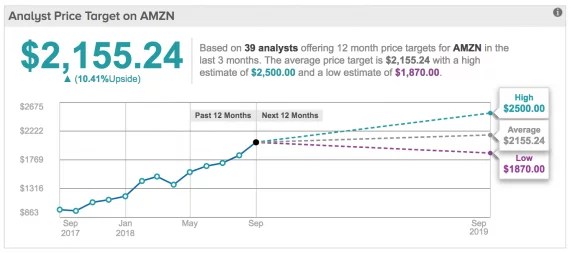 लोकप्रिय सेवा टिपरैंक्स.कॉम से पूर्वानुमान - स्टॉकर की भविष्यवाणी से 10 अंतर खोजें
लोकप्रिय सेवा टिपरैंक्स.कॉम से पूर्वानुमान - स्टॉकर की भविष्यवाणी से 10 अंतर खोजें
जैसा कि अपेक्षित था, समय के साथ अनिश्चितता बढ़ती जाती है। वास्तव में, यदि हम वास्तविक व्यापार के लिए वर्णित दृष्टिकोण का उपयोग करते हैं, तो हम हर दिन एक नया मॉडल प्रशिक्षित करेंगे और एक दिन से अधिक की अवधि के लिए पूर्वानुमान लगाएंगे।
जो कोई भी कोड आज़माना चाहता है, या स्टॉकर के साथ प्रयोग करना चाहता है, उसका GitHub में स्वागत है।