Кодировка Unicode. Использование кодировки юникод
Юникод
Логотип Unicode Consortium
Юникод (чаще всего) или Уникод (англ. Unicode ) - стандарт кодирования символов, позволяющий представить знаки почти всех письменных языков.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc. ).
Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set ) и семейство кодировок (англ. UTF, Unicode transformation format ).
Универсальный набор символов задаёт однозначное соответствие символов кодам - элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
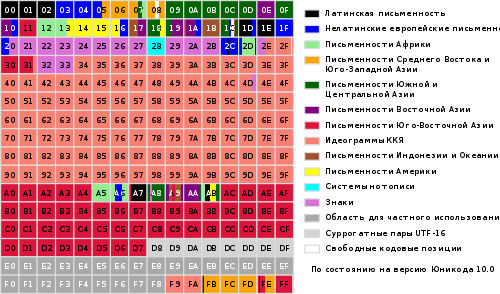
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы.
Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде).
- 1 Предпосылки создания и развитие Юникода
- 2 Версии Юникода
- 3 Кодовое пространство
- 4 Система кодирования
- 4.1 Политика консорциума
- 4.2 Объединение и дублирование символов
- 5 Модифицирующие символы
- 6 Алгоритмы нормализации
- 6.1 NFD
- 6.2 NFC
- 6.3 NFKD
- 6.4 NFKC
- 6.5 Примеры
- 7 Двунаправленное письмо
- 8 Представленные символы
- 9 ISO/IEC 10646
- 10 Способы представления
- 10.1 UTF-8
- 10.2 Порядок байтов
- 10.3 Юникод и традиционные кодировки
- 10.4 Реализации
- 11 Методы ввода
- 11.1 Microsoft Windows
- 11.2 Macintosh
- 11.3 GNU/Linux
- 12 Проблемы Юникода
- 13 «Юникод» или «Уникод»?
Предпосылки создания и развитие Юникода
К концу 1980-х годов стандартом стали 8-битные символы. При этом существовало множество разных 8-битных кодировок, и постоянно появлялись всё новые.
Это объяснялось как постоянным расширением круга поддерживаемых языков, так и стремлением создать кодировку, частично совместимую с какой-нибудь другой (характерный пример - появление альтернативной кодировки для русского языка, обусловленное эксплуатацией западных программ, созданных для кодировки CP437).
В результате появилось несколько проблем:
- проблема «кракозябр»;
- проблема ограниченности набора символов;
- проблема преобразования одной кодировки в другую;
- проблема дублирования шрифтов.
Проблема «кракозябр» - проблема отображения документов в неправильной кодировке. Проблему можно было решить либо последовательным внедрением методов указания используемой кодировки, либо внедрением единой (общей) для всех кодировки.
Проблема ограниченности набора символов . Проблему можно было решить либо переключением шрифтов внутри документа, либо внедрением «широкой» кодировки. Переключение шрифтов издавна практиковалось в текстовых процессорах, причём часто использовались шрифты с нестандартной кодировкой, т. н. «dingbat fonts». В итоге при попытке переноса документа в другую систему все нестандартные символы превращались в «кракозябры».
Проблема преобразования одной кодировки в другую . Проблему можно было решить либо составлением таблиц перекодировки для каждой пары кодировок, либо использованием промежуточного преобразования в третью кодировку, включающую все символы всех кодировок.
Проблема дублирования шрифтов . Для каждой кодировки создавался свой шрифт, даже если наборы символов в кодировках совпадали частично или полностью. Проблему можно было решить путём создания «больших» шрифтов, из которых впоследствии выбирались бы нужные для данной кодировки символы. Однако это требовало создания единого реестра символов, чтобы определять, чему что соответствует.
Была признана необходимость создания единой «широкой» кодировки. Кодировки с переменной длиной символа, широко использующиеся в Восточной Азии, были признаны слишком сложными в использовании, поэтому было решено использовать символы фиксированной ширины.
Использование 32-битных символов казалось слишком расточительным, поэтому было решено использовать 16-битные.
Первая версия Юникода представляла собой кодировку с фиксированным размером символа в 16 бит, то есть общее число кодов было 2 16 (65 536). С тех пор символы стали обозначать четырьмя шестнадцатеричными цифрами (например, U+04F0 ). При этом в Юникоде планировалось кодировать не все существующие символы, а только те, которые необходимы в повседневном обиходе. Редко используемые символы должны были размещаться в «области пользовательских символов» (private use area ), которая первоначально занимала коды U+D800…U+F8FF .
Чтобы использовать Юникод также и в качестве промежуточного звена при преобразовании разных кодировок друг в друга, в него включили все символы, представленные во всех наиболее известных кодировках.
В дальнейшем, однако, было принято решение кодировать все символы и в связи с этим значительно расширить кодовую область.
Одновременно с этим коды символов стали рассматриваться не как 16-битные значения, а как абстрактные числа, которые в компьютере могут представляться множеством разных способов (см. способы представления).
Поскольку в ряде компьютерных систем (например, Windows NT) фиксированные 16-битные символы уже использовались в качестве кодировки по умолчанию, было решено все наиболее важные знаки кодировать только в пределах первых 65 536 позиций (так называемая англ. basic multilingual plane, BMP ).
Остальное пространство используется для «дополнительных символов» (англ. supplementary characters ): систем письма вымерших языков или очень редко используемых китайских иероглифов, математических и музыкальных символов.
Для совместимости со старыми 16-битными системами была изобретена система UTF-16, где первые 65 536 позиций, за исключением позиций из интервала U+D800…U+DFFF, отображаются непосредственно как 16-битные числа, а остальные представляются в виде «суррогатных пар» (первый элемент пары из области U+D800…U+DBFF, второй элемент пары из области U+DC00…U+DFFF). Для суррогатных пар была использована часть кодового пространства (2048 позиций), отведённого «для частного использования».
Поскольку в UTF-16 можно отобразить только 2 20 +2 16 −2048 (1 112 064) символов, то это число и было выбрано в качестве окончательной величины кодового пространства Юникода (диапазон кодов: 0×000000-0x10FFFF).
Хотя кодовая область Юникода была расширена за пределы 2 16 уже в версии 2.0, первые символы в «верхней» области были размещены только в версии 3.1.
Роль этой кодировки в веб-секторе постоянно растёт. На начало 2010 доля веб-сайтов, использующих Юникод, составила около 50 %.
Версии Юникода
Работа по доработке стандарта продолжается. Новые версии выпускаются по мере изменения и пополнения таблиц символов. Параллельно выпускаются новые документы ISO/IEC 10646.
Первый стандарт выпущен в 1991 году, последний - в 2016, следующий ожидается летом 2017 года. Стандарты версий 1.0-5.0 публиковались как книги, и имеют ISBN.
Номер версии стандарта составлен из трёх цифр (например, «4.0.1»). Третью цифру меняют при внесении в стандарт небольших изменений, не добавляющих новых символов.
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до 2 31 (2 147 483 648) кодовых позиций, было принято решение использовать лишь 1 112 064 для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно - в версии 6.0 используется чуть менее 110 000 кодовых позиций (109 242 графических и 273 прочих символа).
Кодовое пространство разбито на 17 плоскостей (англ. planes ) по 2 16 (65 536) символов. Нулевая плоскость (plane 0 ) называется базовой (basic ) и содержит символы наиболее употребительных письменностей. Остальные плоскости - дополнительные (supplementary ). Первая плоскость (plane 1 ) используется в основном для исторических письменностей, вторая (plane 2 ) - для редко используемых иероглифов китайского письма (ККЯ), третья (plane 3 ) зарезервирована для архаичных китайских иероглифов. Плоскости 15 и 16 выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx » (для кодов 0…FFFF), или «U+xxxxx » (для кодов 10000…FFFFF), или «U+xxxxxx » (для кодов 100000…10FFFF), где xxx - шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код 044F 16 = 1103 10 .
Система кодирования
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы - это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают в себя следующие группы:
- буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов;
- цифры;
- знаки пунктуации;
- специальные знаки (математические, технические, идеограммы и пр.);
- разделители.
Юникод - это система для линейного представления текста. Символы, имеющие дополнительные над- или подстрочные элементы, могут быть представлены в виде построенной по определённым правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character). На данный момент (2014) считается, что все буквы крупных письменностей в Юникод внесены, и если символ доступен в составном варианте, дублировать его в монолитном виде не нужно.
Политика консорциума
Консорциум не создаёт нового, а констатирует сложившийся порядок вещей. Например, картинки «эмодзи» были добавлены потому, что японские операторы мобильной связи широко их использовали.
Для этого добавление символа проходит через сложный процесс. И, например, символ российского рубля прошёл его за три месяца просто потому, что получил официальный статус.
Товарные знаки кодируют только в порядке исключения. Так, в Юникоде нет флага Windows или яблока Apple.
Как только символ появился в кодировке, он никогда не сдвинется и не исчезнет. Если же потребуется изменить порядок символов, это делается не переменой позиций, а национальным порядком сортировки. Есть и другие, более тонкие гарантии стабильности - например, не будут меняться таблицы нормализации.
Объединение и дублирование символов
Один и тот же символ может иметь несколько форм; в Юникод эти формы входят одной кодовой позицией:
- если это сложилось исторически. Например, у арабских букв есть четыре формы: обособленная, в начале, в середине и в конце;
- либо если в одном языке принята одна форма, а в другом - другая. Болгарская кириллица отличается от русской, а китайские иероглифы - от японских.
С другой стороны, если исторически в шрифтах были две разных кодовых позиции, они остаются разными и в Юникоде. Строчная греческая сигма имеет две формы, и у них разные позиции. Буква расширенной латиницы Å (A с кружком ) и знак ангстрема Å, греческая буква μ и обозначение приставки «микро-» µ - разные символы.
Конечно же, похожие символы в неродственных письменностях ставятся в разные кодовые позиции. Например, буква А в латинице, кириллице, греческом и чероки - разные символы.
Крайне редко один и тот же символ ставится в две разные кодовые позиции для упрощения обработки текста. Математический штрих и такой же штрих для индикации мягкости звуков - разные символы, второй считается буквой.
Модифицирующие символы
Представление символа «Й» (U+0419) в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306)
Графические символы в Юникоде подразделяются на протяжённые и непротяжённые (бесширинные). Непротяжённые символы при отображении не занимают места в строке. К ним относятся, в частности, знаки ударения и прочие диакритические знаки. Как протяжённые, так и непротяжённые символы имеют собственные коды. Протяжённые символы иначе называются базовыми (англ. base characters ), а непротяжённые - модифицирующими (англ. combining characters ); причём последние не могут встречаться самостоятельно. Например, символ «á» может быть представлен как последовательность базового символа «a» (U+0061) и модифицирующего символа « ́» (U+0301) или как монолитный символ «á» (U+00E1).
Особый тип модифицирующих символов - селекторы варианта начертания (англ. variation selectors ). Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов монгольского квадратного письма.
Алгоритмы нормализации
Поскольку одни и те же символы можно представить различными кодами, сравнение строк байт за байтом становится невозможным. Алгоритмы нормализации (англ. normalization forms ) решают эту проблему, выполняя приведение текста к определённому стандартному виду.
Приведение осуществляется путём замены символов на эквивалентные с использованием таблиц и правил. «Декомпозицией» называется замена (разложение) одного символа на несколько составляющих символов, а «композицией», наоборот, - замена (соединение) нескольких составляющих символов на один символ.
В стандарте Юникода определены 4 алгоритма нормализации текста: NFD, NFC, NFKD и NFKC.
NFD
NFD, англ. n ormalization f orm D («D» от англ. d ecomposition ), форма нормализации D - каноническая декомпозиция - алгоритм, согласно которому выполняется рекурсивная замена монолитных символов (англ. precomposed characters ) на несколько составных (англ. composite characters ) в соответствии с таблицами декомпозиции.
Å U+00C5 →
A U+0041
̊ U+030A
ṩ U+1E69 →
s U+0073
̣ U+0323
̇ U+0307
ḍ̇ U+1E0B U+0323 →
d U+0064
̣ U+0323
̇ U+0307
q̣̇ U+0071 U+0307 U+0323 →
q U+0071
̣ U+0323
̇ U+0307 NFC
NFC, англ. n ormalization f orm C («C» от англ. c omposition ), форма нормализации C - алгоритм, согласно которому последовательно выполняются каноническая декомпозиция и каноническая композиция. Сначала каноническая декомпозиция (алгоритм NFD) приводит текст к форме D. Затем каноническая композиция - операция, обратная NFD, обрабатывает текст от начала к концу с учётом следующих правил:
- символ S считается начальным , если имеет класс модификации равный нулю согласно таблице символов Юникода;
- в любой последовательности символов, начинающейся с символа S , символ C блокируется от S , только если между S и C есть какой-либо символ B , который либо является начальным, либо имеет одинаковый или больший класс модификации, чем C . Это правило распространяется только на строки, прошедшие каноническую декомпозицию;
- символ считается первичным композитом, если имеет каноническую декомпозицию в таблице символов Юникода (или каноническую декомпозицию для хангыля и он не входит в список исключений);
- символ X может быть первично совмещён с символом Y , если и только если существует первичный композит Z , канонически эквивалентный последовательности <X , Y >;
- если очередной символ C не блокируется последним встреченным начальным базовым символом L и он может быть успешно первично совмещён с ним, то L заменяется на композит L-C , а C удаляется.
o U+006F
̂ U+0302 → →
H U+0048
① U+2460 →
1 U+0031
カ U+FF76 →
カ U+30AB →
fi U+FB01
fi U+FB01
f i U+0066 U+0069
f i U+0066 U+0069
2 ⁵ U+0032 U+2075
2 ⁵ U+0032 U+2075
2 ⁵ U+0032 U+2075
2 5 U+0032 U+0035
2 5 U+0032 U+0035
ẛ̣ U+1E9B U+0323
ſ ̣ ̇ U+017F U+0323 U+0307
ẛ ̣ U+1E9B U+0323
s ̣ ̇ U+0073 U+0323 U+0307
ṩ U+1E69
й U+0439
и ̆ U+0438 U+0306
й U+0439
и ̆ U+0438 U+0306
й U+0439
ё U+0451
е ̈ U+0435 U+0308
ё U+0451
е ̈ U+0435 U+0308
ё U+0451
А U+0410
А U+0410
А U+0410
А U+0410
А U+0410
が U+304C
か ゙ U+304B U+3099
が U+304C
か ゙ U+304B U+3099
が U+304C
Ⅷ U+2167
Ⅷ U+2167
Ⅷ U+2167
V I I I U+0056 U+0049 U+0049 U+0049
V I I I U+0056 U+0049 U+0049 U+0049
ç U+00E7
c ̧ U+0063 U+0327
ç U+00E7
c ̧ U+0063 U+0327
ç U+00E7 Двунаправленное письмо
Стандарт Юникод поддерживает письменности языков как с направлением написания слева направо (англ. left-to-right, LTR ), так и с написанием справа налево (англ. right-to-left, RTL ) - например, арабское и еврейское письмо. В обоих случаях символы хранятся в «естественном» порядке; их отображение с учётом нужного направления письма обеспечивается приложением.
Кроме того, Юникод поддерживает комбинированные тексты, сочетающие фрагменты с разным направлением письма. Данная возможность называется двунаправленность (англ. bidirectional text, BiDi ). Некоторые упрощённые обработчики текста (например, в сотовых телефонах) могут поддерживать Юникод, но не иметь поддержки двунаправленности. Все символы Юникода поделены на несколько категорий: пишущиеся слева направо, пишущиеся справа налево, и пишущиеся в любом направлении. Символы последней категории (в основном это знаки пунктуации) при отображении принимают направление окружающего их текста.
Представленные символы
Схема основной мультиязычной плоскости Юникода
Юникод включает практически все современные письменности, в том числе:
- арабскую,
- армянскую,
- бенгальскую,
- бирманскую,
- глаголицу,
- греческую,
- грузинскую,
- деванагари,
- еврейскую,
- кириллицу,
- китайскую (китайские иероглифы активно используются в японском языке, а также изредка в корейском),
- коптскую,
- кхмерскую,
- латинскую,
- тамильскую,
- корейскую (хангыль),
- чероки,
- эфиопскую,
- японскую (которая включает в себя, кроме слоговой азбуки, ещё и китайские иероглифы)
и другие.
С академическими целями добавлены многие исторические письменности, в том числе: германские руны, древнетюркские руны, древнегреческая письменность, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
В Юникод принципиально не включаются государственные флаги, логотипы компаний и продуктов, хотя они и встречаются в шрифтах (например, логотип Apple в кодировке MacRoman (0xF0) или логотип Windows в шрифте Wingdings (0xFF)). В юникодовских шрифтах логотипы должны размещаться только в области пользовательских символов.
ISO/IEC 10646
Консорциум Юникода работает в тесной связи с рабочей группой ISO/IEC/JTC1/SC2/WG2, которая занимается разработкой международного стандарта 10646 (ISO/IEC 10646). Между стандартом Юникода и ISO/IEC 10646 установлена синхронизация, хотя каждый стандарт использует свою терминологию и систему документации.
Сотрудничество Консорциума Юникода с Международной организацией по стандартизации (англ. International Organization for Standardization, ISO ) началось в 1991 году. В 1993 году ISO выпустила стандарт DIS 10646.1. Для синхронизации с ним Консорциум утвердил стандарт Юникода версии 1.1, в который были внесены дополнительные символы из DIS 10646.1. В результате значения закодированных символов в Unicode 1.1 и DIS 10646.1 полностью совпали.
В дальнейшем сотрудничество двух организаций продолжилось. В 2000 году стандарт Unicode 3.0 был синхронизирован с ISO/IEC 10646-1:2000. Предстоящая третья версия ISO/IEC 10646 будет синхронизирована с Unicode 4.0. Возможно, эти спецификации даже будут опубликованы как единый стандарт.
Аналогично форматам UTF-16 и UTF-32 в стандарте Юникода, стандарт ISO/IEC 10646 также имеет две основные формы кодирования символов: UCS-2 (2 байта на символ, аналогично UTF-16) и UCS-4 (4 байта на символ, аналогично UTF-32). UCS значит универсальный многооктетный (многобайтовый) кодированный набор символов (англ. universal multiple-octet coded character set ). UCS-2 можно считать подмножеством UTF-16 (UTF-16 без суррогатных пар), а UCS-4 является синонимом для UTF-32.
Отличия стандартов Юникод и ISO/IEC 10646:
- небольшие различия в терминологии;
- ISO/IEC 10646 не включает разделы, необходимые для полноценной реализации поддержки Юникода:
- нет данных о двоичном кодировании символов;
- нет описания алгоритмов сравнения (англ. collation ) и отрисовки (англ. rendering ) символов;
- нет перечня свойств символов (например, нет перечня свойств, необходимых для реализации поддержки двунаправленного (англ. bi-directional ) письма).
Способы представления
Юникод имеет несколько форм представления (англ. Unicode transformation format, UTF ): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. 1 апреля 2005 года были предложены две шуточные формы представления: UTF-9 и UTF-18 (RFC 4042).
В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
Punycode - другая форма кодирования последовательностей Unicode-символов в так называемые ACE-последовательности, которые состоят только из алфавитно-цифровых символов, как это разрешено в доменных именах.
UTF-8
UTF-8 - представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими 8-битные символы.
Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом.
Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт (на деле, только до 4 байт, поскольку в Юникоде нет символов с кодом больше 10FFFF, и вводить их в будущем не планируется), в которых первый байт всегда имеет вид 11xxxxxx , а остальные - 10xxxxxx . В UTF-8 не используются суррогатные пары, 4 байтов достаточно для записи любого символа юникода.
Формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9 . Сейчас стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
Символы UTF-8 получаются из Unicode следующим образом:
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Теоретически возможны, но не включены в стандарт также:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы должны отвергаться по соображениям безопасности.
Порядок байтов
В потоке данных UTF-16 младший байт может записываться либо перед старшим (англ. UTF-16 little-endian ), либо после старшего (англ. UTF-16 big-endian ). Аналогично существует два варианта четырёхбайтной кодировки - UTF-32LE и UTF-32BE.
Для определения формата представления Юникода в начало текстового файла записывается сигнатура - символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байтов (англ. byte order mark (BOM) ). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует. Также этот способ иногда применяется для обозначения формата UTF-8, хотя к этому формату и неприменимо понятие порядка байтов. Файлы, следующие этому соглашению, начинаются с таких последовательностей байтов:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом (хотя реальные тексты редко начинаются с него).
Файлы в кодировках UTF-16 и UTF-32, не содержащие BOM, должны иметь порядок байтов big-endian (unicode.org).
Юникод и традиционные кодировки
Внедрение Юникода привело к изменению подхода к традиционным 8-битным кодировкам. Если раньше кодировка задавалась шрифтом, то теперь она задаётся таблицей соответствия между данной кодировкой и Юникодом.
Фактически 8-битные кодировки превратились в форму представления некоторого подмножества Юникода. Это намного упростило создание программ, которые должны работать с множеством разных кодировок: теперь, чтобы добавить поддержку ещё одной кодировки, надо всего лишь добавить ещё одну таблицу перекодировки в Юникод.
Кроме того, многие форматы данных позволяют вставлять любые символы Юникода, даже если документ записан в старой 8-битной кодировке. Например, в HTML можно использовать коды с амперсандом.
Реализации
Большинство современных операционных систем в той или иной степени обеспечивают поддержку Юникода.
В операционных системах семейства Windows NT для внутреннего представления имён файлов и других системных строк используется двухбайтовая кодировка UTF-16LE. Системные вызовы, принимающие строковые параметры, существуют в однобайтном и двухбайтном вариантах. Подробнее см. в статье Юникод в операционных системах семейства Microsoft Windows.
UNIX-подобные операционные системы, в том числе GNU/Linux, BSD, OS X, используют для представления Юникода кодировку UTF-8. Большинство программ могут работать с UTF-8 как с традиционными однобайтными кодировками, не обращая внимания на то, что символ представляется как несколько последовательных байт. Для работы с отдельными символами строки обычно перекодируются в UCS-4, так что каждому символу соответствует машинное слово.
Одной из первых успешных коммерческих реализаций Юникода стала среда программирования Java. В ней принципиально отказались от 8-битного представления символов в пользу 16-битного. Это решение увеличивало расход памяти, но позволило вернуть в программирование важную абстракцию: произвольный одиночный символ (тип char ). В частности, программист мог работать со строкой, как с простым массивом. К сожалению, успех не был окончательным, Юникод перерос ограничение в 16 бит и к версии J2SE 5.0 произвольный символ снова стал занимать переменное число единиц памяти - один char или два (см. суррогатная пара).
Сейчас большинство языков программирования поддерживают строки Юникода, хотя их представление может различаться в зависимости от реализации.
Методы ввода
Поскольку ни одна раскладка клавиатуры не может позволить вводить все символы Юникода одновременно, от операционных систем и прикладных программ требуется поддержка альтернативных методов ввода произвольных символов Юникода.
Microsoft Windows
Хотя начиная с Windows 2000, служебная программа «Таблица символов» (charmap.exe) поддерживает символы Юникода и позволяет копировать их в буфер обмена, но эта поддержка ограничена только базовой плоскостью (коды символов U+0000…U+FFFF). Символы с кодами от U+10000 «Таблица символов» не отображает.
Похожая таблица есть, например, в Microsoft Word.
Иногда можно набрать шестнадцатеричный код, нажать Alt + X , и код будет заменён на соответствующий символ, например, в WordPad, Microsoft Word. В редакторах Alt + X выполняет и обратное преобразование.
Во многих программах MS Windows, чтобы получить символ Unicode, нужно при нажатой клавише Alt набрать десятичное значение кода символа на цифровой клавиатуре. Например, полезными при наборе кириллических текстов будут комбинации Alt+0171 («), Alt+0187 (») и Alt+0769 (знак ударения). Интересны также комбинации Alt+0133 (…) и Alt+0151 (-).
Macintosh
В Mac OS 8.5 и более поздних версиях поддерживается метод ввода, называемый «Unicode Hex Input». При зажатой клавише Option требуется набрать четырёхзначный шестнадцатеричный код требуемого символа. Этот метод позволяет вводить символы с кодами, большими U+FFFF, используя пары суррогатов; такие пары операционной системой будут автоматически заменены на одиночные символы. Этот метод ввода перед использованием нужно активизировать в соответствующем разделе системных настроек и затем выбрать как текущий метод ввода в меню клавиатуры.
Начиная с Mac OS X 10.2, существует также приложение «Character Palette», позволяющее выбирать символы из таблицы, в которой можно выделять символы определённого блока или символы, поддерживаемые конкретным шрифтом.
GNU/Linux
В GNOME также есть утилита «Таблица символов» (ранее gucharmap), позволяющая отображать символы определённого блока или системы письма и предоставляющая возможность поиска по названию или описанию символа. Когда код нужного символа известен, его можно ввести в соответствии со стандартом ISO 14755: при зажатых клавишах Ctrl + ⇧ Shift ввести шестнадцатеричный код (начиная с некоторой версии GTK+, ввод кода нужно предварить нажатием клавиши «U» ). Вводимый шестнадцатеричный код может иметь до 32 бит в длину, позволяя вводить любые символы Юникода без использования суррогатных пар.
Все приложения X Window, включая GNOME и KDE, поддерживают ввод при помощи клавиши Compose . Для клавиатур, на которых нет отдельной клавиши Compose, для этой цели можно назначить любую клавишу - например, ⇪ Caps Lock .
Консоль GNU/Linux также допускает ввод символа Юникода по его коду - для этого десятичный код символа нужно ввести цифрами расширенного блока клавиатуры при зажатой клавише Alt . Можно вводить символы и по их шестнадцатеричному коду: для этого нужно зажать клавишу AltGr , и для ввода цифр A-F использовать клавиши расширенного блока клавиатуры от NumLock до ↵ Enter (по часовой стрелке). Поддерживается также и ввод в соответствии с ISO 14755. Для того чтобы перечисленные способы могли работать, нужно включить в консоли режим Юникода вызовом unicode_start (1) и выбрать подходящий шрифт вызовом setfont (8).
Mozilla Firefox для Linux поддерживает ввод символов по ISO 14755.
Проблемы Юникода
В Юникоде английское «a» и польское «a» - один и тот же символ. Точно так же одним и тем же символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
- Тексты на китайском, корейском и японском языках имеют традиционное написание сверху вниз, начиная с правого верхнего угла. Переключение горизонтального и вертикального написания для этих языков не предусмотрено в Юникоде - это должно осуществляться средствами языков разметки или внутренними механизмами текстовых процессоров.
- Юникод предусматривает возможность разных начертаний одного и того же символа в зависимости от языка. Так, китайские иероглифы могут иметь разные начертания в китайском, японском (кандзи) и корейском (ханча), но при этом в Юникоде обозначаются одним и тем же символом (так называемая CJK-унификация), хотя упрощённые и полные иероглифы всё же имеют разные коды. Аналогично, русский и сербский языки используют разное начертание курсивных букв п и т (в сербском они выглядят как и и ш , см. сербский курсив). Поэтому нужно следить, чтобы текст всегда был правильно помечен как относящийся к тому или другому языку.
- Перевод из строчных букв в заглавные тоже зависит от языка. Например: в турецком существуют буквы İi и Iı - таким образом, турецкие правила изменения регистра конфликтуют с английскими, которые предписывают «i» переводить в «I». Подобные проблемы есть и в других языках - например, в канадском диалекте французского языка регистр переводится немного не так, как во Франции.
- Даже с арабскими цифрами есть определённые типографские тонкости: цифры бывают «прописными» и «строчными», пропорциональными и моноширинными - для Юникода разницы между ними нет. Подобные нюансы остаются за программным обеспечением.
Некоторые недостатки связаны не с самим Юникодом, а с возможностями обработчиков текста.
- Файлы нелатинского текста в Юникоде всегда занимают больше места, так как один символ кодируется не одним байтом, как в различных национальных кодировках, а последовательностью байтов (исключение составляет UTF-8 для языков, алфавит которых укладывается в ASCII, а также наличие в тексте символов двух и более языков, алфавит которых не укладывается в ASCII). Файл шрифта, необходимый для отображения всех символов таблицы Юникод, занимает сравнительно много места в памяти и требует бо́льших вычислительных ресурсов, чем шрифт только одного национального языка пользователя. С увеличением мощности компьютерных систем и удешевлением памяти и дискового пространства эта проблема становится всё менее существенной; тем не менее, она остаётся актуальной для портативных устройств, например, для мобильных телефонов.
- Хотя поддержка Юникода реализована в наиболее распространённых операционных системах, до сих пор не всё прикладное программное обеспечение поддерживает корректную работу с ним. В частности, не всегда обрабатываются метки порядка байтов (BOM) и плохо поддерживаются диакритические символы. Проблема является временной и есть следствие сравнительной новизны стандартов Юникода (в сравнении с однобайтовыми национальными кодировками).
- Производительность всех программ обработки строк (в том числе и сортировок в БД) снижается при использовании Юникода вместо однобайтовых кодировок.
Некоторые редкие системы письма всё ещё не представлены должным образом в Юникоде. Изображение «длинных» надстрочных символов, простирающихся над несколькими буквами, как, например, в церковнославянском языке, пока не реализовано.
«Юникод» или «Уникод»?
«Unicode» - одновременно и имя собственное (или часть имени, например, Unicode Consortium), и имя нарицательное, происходящее из английского языка.
На первый взгляд предпочтительнее использовать написание «Уникод». В русском языке уже есть морфемы «уни-» (слова с латинским элементом «uni-» традиционно переводились и писались через «уни-»: универсальный, униполярный, унификация, униформа) и «код». Напротив, торговые марки, заимствованные из английского языка, обычно передаются посредством практической транскрипции, в которой деэтимологизированное сочетание букв «uni-» записывается в виде «юни-» («Юнилевер», «Юникс» и т. п.), то есть точно так же, как в случае с побуквенными сокращениями, вроде UNICEF «United Nations International Children’s Emergency Fund» - ЮНИСЕФ.
Написание «Юникод» уже твёрдо вошло в русскоязычные тексты. В Википедии используется более распространённый вариант. В MS Windows используется вариант «Юникод».
На сайте Консорциума есть специальная страница, где рассматриваются проблемы передачи слова «Unicode» в различных языках и системах письма. Для русской кириллицы указан вариант «Юникод».

Проблемы, связанные с кодировками, обычно берёт на себя программное обеспечение, поэтому обычно не возникает никаких сложностей с использованием кодировок. Если же сложности возникают, то они обычно порождаются плохими программами — смело отправляйте их в корзину.
Приглашаю всех высказываться в
Эта документация перемещена в архив и не поддерживается.
Использование кодировки Юникод
.NET Framework 3.5
Обновлен: Ноябрь 2007
В приложениях, ориентированных на общую среду исполнения, для преобразования символов из внутреннего представления (Юникод) в другой вид используется кодирование. Для обратного преобразования знаков из внешних кодировок (не Юникод) во внутреннее представление используется декодирование. Пространство имен располагает рядом классов, позволяющих приложениям кодировать и декодировать символы. Общие сведения об этих классах см. в разделе .
Стандарт Юникода присваивает каждому символу в каждом поддерживаемом сценарии кодовую позицию (номер). UTF– это формат, используемый для кодирования кодовой точки. Стандарт Юникода версии 3.2 использует форматы преобразования (UTF) и другие кодировки, перечисленные в следующей таблице. Для всех кодировок встроенные строки.NET Framework являются собственными строками UTF-16.
Кодировка Юникода UTF-32
Представляет символы Юникода в виде последовательности 32-разрядных целых чисел. Приложение может использовать класс для преобразования символов в формат кодировки UTF-32 и обратно.
UTF-32 используется в случае, когда приложению необходимо избежать поведения замещающей кодовой точки UTF-16 в операционных системах, где закодированное пространство имеет большое значение. Обратите внимание, что для кодировки отдельных отображаемых "глифов" может использоваться несколько символов UTF-32. Дополнительные символы, подверженные влиянию такого поведения, встречаются реже, чем символы BMP Юникода.
Кодировка Юникода UTF-16
Представляет символы Юникода в виде последовательности 16-разрядных целых чисел. Приложение может использовать класс для преобразования символов в формат кодировки UTF-16 и обратно.
UTF-16 часто используется в виде встроенного формата, как тип Microsoft.Net char , тип Windows WCHAR и другие общие типы. Большинство распространенных кодовых точек Юникода принимают только одну кодовую точку UTF-16 (2 байта). Для дополнительных символов Юникода U+10000 и выше по-прежнему требуется две замещающие кодовые точки UTF.
Кодировка Юникода UTF-8
Представляет символы Юникод в виде последовательности длиной 8 бит. Приложение может использовать класс для преобразования символов в формат кодировки UTF-8 и обратно.
UTF-8 предназначен для кодировки с помощью 8-разарядной системы и хорошо работает со многими операционными системами. Для диапазона символов ASCII UTF-8 идентичен кодировке ASCII и представляет более широкий набор символов. Однако для сценариев CJK UTF-8 может потребовать три байта для каждого символа, создавая, таким образом, данные большего размера, чем UTF-16. Обратите внимание, что иногда увеличение размера диапазона CJK объясняется объемом данных ASCII, например тегами HTML.
Кодировка Юникода UTF-7
Представляет символы Юникода в виде последовательности 7-разрядных символов ASCII. Приложение может использовать класс для преобразования символов в формат кодировки UTF-7 и обратно. Символы, отличные от ASCII Юникода, представлены в виде escape-последовательности символов ASCII.
UTF-7 поддерживает определенные протоколы, для которых он необходим. Чаще всего это протоколы электронной почты и групп новостей. Однако формат UTF-7 недостаточно безопасен или надежен. В некоторых случаях изменение одного бита может привести к существенному изменению интерпретации всей строки UTF-7. В других ситуациях для кодировки одного и того же текста могут использоваться разные строки UTF-7. В последовательностях, содержащих отличные от ASCII символы, формат UTF-7 гораздо менее эффективно использует пространство, чем UTF-8, и процесс кодирования/декодирования выполняется медленнее. Следовательно, формат UTF-8 является более предпочтительным для работы в приложениях.
Кодировка ASCII
В кодировке ASCII знаки латинского алфавита кодируются как 7-разрядные символы ASCII. Так как эта кодировка поддерживает только значения символов от U+0000 до U+007F, то во многих случаях она не отвечает требованиям международных приложений. Приложение может использовать класс для преобразования символов в формат кодировки ASII и обратно. Примеры использования этого класса в коде см. в разделе .
Кодировки ANSI и ISO
Используются для кодировки, отличной от Юникод. Класс поддерживает широкий диапазон кодировок ANSI/ISO.
Произвольные коллекции чисел (байт или символов) не являются допустимыми строками или коллекциями Юникода. Приложение не может преобразовать массив байтов в формат Юникода и обратно, поэтому он работать не будет. Определенные последовательности символов и кодовых позиций не поддерживаются в Юникод 5.0 и не могут быть преобразованы с помощью кодировок Юникода. Если приложение должно передать данные в двоичном формате, следует использовать базовый 64 или другой формат, предназначенный для этой цели.
Чтобы вернуть требуемый объект кодировки для указанной кодировки, в приложении можно использовать метод . Для преобразования строки Юникода в ее байтовое представление в указанной кодировке используется метод .
Приведенный ниже пример кода использует метод GetEncoding необходимого объекта кодировки для конкретной кодовой страницы. Метод GetBytes вызывается для нужного объекта кодировки для преобразования строки Юникода в байтовое представление в требуемой кодировке. На экране будет отображено байтовое представление строки на конкретной кодовой странице.
using System; using System.IO; using System.Globalization; using System.Text; public class Encoding_UnicodeToCP { public static void Main() { // Converts ASCII characters to bytes. // Displays the string"s byte representation in the // specified code page. // Code page 1252 represents Latin characters. PrintCPBytes("Hello, World!" ,1252); // Code page 932 represents Japanese characters. PrintCPBytes("Hello, World!" ,932); // Converts Japanese characters to bytes. PrintCPBytes(,1252); PrintCPBytes("\u307b,\u308b,\u305a,\u3042,\u306d" ,932); } public static void PrintCPBytes(string str, int codePage) { Encoding targetEncoding; byte encodedChars; // Gets the encoding for the specified code page. targetEncoding = Encoding.GetEncoding(codePage); // Gets the byte representation of the specified string. encodedChars = targetEncoding.GetBytes(str); // Prints the bytes. Console.WriteLine ("Byte representation of "{0}" in Code Page "{1}":" , str, codePage); for (int i = 0; i < encodedChars.Length; i++) Console.WriteLine("Byte {0}: {1}" , i, encodedChars[i]); } }
При использовании данного кода в консольном приложении указанные текстовые элементы Юникода могут отображаться неправильно. Поддержка символов Юникода в консольной среде зависит от установленной версии операционной системы Windows. |
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам - элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
Стандарт Unicode был разработан с целью создания единой кодировки символов всех современных и многих древних письменных языков. Каждый символ в этом стандарте кодируется 16 битами, что позволяет ему охватить несравненно большее количество символов, чем принятые ранее 8-битовые кодировки. Еще одним важным отличием Unicode от других систем кодировки является то, что он не только приписывает каждому символу уникальный код, но и определяет различные характеристики этого символа, например:
Тип символа (прописная буква, строчная буква, цифра, знак препинания и т.д.);
Атрибуты символа (отображение слева направо или справа налево, пробел, разрыв строки и т.д.);
Соответствующая прописная или строчная буква (для строчных и прописных букв соответственно);
Соответствующее числовое значение (для цифровых символов).
Весь диапазон кодов от 0 до FFFF разбит на несколько стандартных подмножеств, каждое из которых соответствует либо алфавиту какого-то языка, либо группе специальных символов, сходных по своим функциям. На приведенной ниже схеме содержится общий перечень подмножеств Unicode 3.0 (рисунок 2).
Рисунок 2
Стандарт Unicode является основой для хранения и текста во многих современных компьютерных системах. Однако, он не совместим с большинством Интернет-протоколов, поскольку его коды могут содержать любые байтовые значения, а протоколы обычно используют байты 00 - 1F и FE - FF в качестве служебных. Для достижения совместимости были разработаны несколько форматов преобразования Unicode (UTFs, Unicode Transformation Formats), из которых на сегодня наиболее распространенным является UTF-8. Этот формат определяет следующие правила преобразования каждого кода Unicode в набор байтов (от одного до трех), пригодных для транспортировки Интернет-протоколами.
Здесь x,y,z обозначают биты исходного кода, которые должны извлекаться, начиная с младшего, и заноситься в байты результата справа налево, пока не будут заполнены все указанные позиции.
Дальнейшее развитие стандарта Unicode связано с добавлением новых языковых плоскостей, т.е. символов в диапазонах 10000 - 1FFFF, 20000 - 2FFFF и т.д., куда предполагается включать кодировку для письменностей мертвых языков, не попавших в таблицу, приведенную выше. Для кодирования этих дополнительных символов был разработан новый формат UTF-16.
Таким образом, существует 4 основных способа кодировки байтами в формате Unicode:
UTF-8: 128 символов кодируются одним байтом (формат ASCII), 1920 символов кодируются 2-мя байтами ((Roman, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic символы), 63488 символов кодируются 3-мя байтами (Китайский, японский и др.) Оставшиеся 2 147 418 112 символы (еще не использованы) могут быть закодированы 4, 5 или 6-ю байтами.
UCS-2: Каждый символ представлен 2-мя байтами. Данная кодировка включает лишь первые 65 535 символов из формата Unicode.
UTF-16:Является расширением UCS-2, включает 1 114 112 символов формата Unicode. Первые 65 535 символов представлены 2-мя байтами, остальные - 4-мя байтами.
USC-4: Каждый символ кодируется 4-мя байтами.
Эта документация перемещена в архив и не поддерживается.
Использование кодировки Юникод
.NET Framework 3.5
Обновлен: Ноябрь 2007
В приложениях, ориентированных на общую среду исполнения, для преобразования символов из внутреннего представления (Юникод) в другой вид используется кодирование. Для обратного преобразования знаков из внешних кодировок (не Юникод) во внутреннее представление используется декодирование. Пространство имен располагает рядом классов, позволяющих приложениям кодировать и декодировать символы. Общие сведения об этих классах см. в разделе .
Кодировки ANSI и ISOИспользуются для кодировки, отличной от Юникод. Класс поддерживает широкий диапазон кодировок ANSI/ISO.
Приведенный ниже пример кода использует метод GetEncoding необходимого объекта кодировки для конкретной кодовой страницы. Метод GetBytes вызывается для нужного объекта кодировки для преобразования строки Юникода в байтовое представление в требуемой кодировке. На экране будет отображено байтовое представление строки на конкретной кодовой странице.
Imports System Imports System.IO Imports System.Globalization Imports System.Text Public Class Encoding_UnicodeToCP Public Shared Sub Main() " Converts ASCII characters to bytes. " Displays the string"s byte representation in the " specified code page. " Code page 1252 represents Latin characters. PrintCPBytes("Hello, World!" , 1252) " Code page 932 represents Japanese characters. PrintCPBytes("Hello, World!" , 932) " Converts Japanese characters. PrintCPBytes(,1252) PrintCPBytes("\u307b,\u308b,\u305a,\u3042,\u306d" ,932) End Sub Public Shared Sub PrintCPBytes(str As String , codePage As Integer ) Dim targetEncoding As Encoding Dim encodedChars() As Byte " Gets the encoding for the specified code page. targetEncoding = Encoding.GetEncoding(codePage) " Gets the byte representation of the specified string. encodedChars = targetEncoding.GetBytes(str) " Prints the bytes. Console.WriteLine("Byte representation of "{0}" in CP "{1}":" , _ str, codePage) Dim i As Integer For i = 0 To encodedChars.Length - 1 Console.WriteLine("Byte {0}: {1}" , i, encodedChars(i)) Next i End Sub End Class
В системе кодирования ASCII (American Standard Code for Information Interchange - стандартный код информационного обмена США) каждый символ представлен одним байтом, что позволяет закодировать 256 символов.
В ASCII имеется две таблицы кодирования - базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и общепринятые специальные символы, которые можно наблюдать на клавиатуре.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных. Начиная с кода 32 по код 127, размещены символы английского алфавита, знаки препинания, цифры, арифметические действия и вспомогательные символы, все их можно видеть на латинской части клавиатуры компьютера.
Вторая, расширенная часть отдана национальным системам кодирования. В мире существует много нелатинских алфавитов (арабский, еврейский, греческий и пр.), в число которых входит и кириллица. Кроме того, немецкая, французская, испанская раскладки клавиатуры отличаются от английской.
В английской части клавиатуры раньше было много стандартов, а теперь все они заменены на единый код ASCII. Для русской клавиатуры тоже существовало много стандартов: ГОСТ, ГОСТ-альтернативная, ISO (International Standard Organization - Международный институт стандартизации), но эти три стандарта фактически уже вымерли, хотя и могут где-то встретиться, в каких-то допотопных компьютерах или в компьютерных сетях.
Основная кодировка символов русского языка, которая используется в компьютерах с операционной системой Windows называется Windows-1251 , она была разработана для алфавитов кириллицы компанией Microsoft. Естественно, что в Windows-1251 закодировано абсолютное большинство компьютерных текстовых данных. Кстати кодировки с другим четырехзначным номером разработаны Microsoft для других распространенных алфавитов: арабского, японского и прочих.
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) - ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы. Сегодня кодировка КОИ-8 имеет распространение в компьютерных сетях на территории России и в российском секторе Интернета. Бывает так, что какой-то текст письма или еще чего-то не читается, это значит, что надо перейти из КОИ-8 в Windows-1251. 10
В 90-х годах крупнейшие производители программного обеспечения: Microsoft, Borland, та же Adobe приняли решение о необходимости разработки другой системы кодировки текста, в которой каждому символу будет отводиться не 1, а 2 байта. Она получила название Unicode , и в ней можно закодировать 65 536 символов этого поля достаточно для размещения в одной таблице национальных алфавитов для всех языков планеты. Большую часть Unicode (около 70%) занимают китайские иероглифы, в Индии имеется 11 различных национальных алфавитов, есть множество экзотических названий, например: письменность канадских аборигенов.
Поскольку на кодирования каждого символа в Unicode отводится не 8, а 16 разрядов, объем текстового файла увеличивается в 2 раза. Когда-то это было препятствием для введения 16-разрядной системы. а сейчас при гигабайтных винчестерах, сотнях мегабайт оперативной памяти, гигагерцных процессорах удвоение объемов текстовых файлов, которые по сравнению, например, с графикой занимают очень немного места, большого значения не имеет.
Кириллица занимает в Unicode места с 768 по 923 (основные знаки) и с 924 по 1023 (расширенная кириллица, различные малораспространенные, национальные буквы). Если программа не адаптирована под кириллицу Unicode, то возможен вариант, когда символы текста распознаются не как кириллица, а как расширенная латиница (коды с 256 по 511). И в этом случае вместо текста на экране появляется бессмысленный набор различных экзотических символов.
Такое возможно, если программа устаревшая, созданная до 1995 года. Или малораспространенная, о русификации которой никто не позаботился. Еще возможен вариант, когда установленная на компьютере ОС Windows не полностью настроена под кириллицу. В этом случае надо сделать соответствующие записи в реестре.