Коды unicode. Unicode-символы, которые можно использовать вместо иконок.
Каждый пользователь Интернета в попытках настроить ту или иную его функцию хотя бы однажды видел на дисплее написанное слово «Юникод». Что это такое, вы узнаете, прочитав эту статью.
Определение
Кодировка "Юникод" — стандарт кодирования символов. Он был предложен некоммерческой организацией Unicode Inc. в 1991 году. Стандарт разработан с целью объединения как можно большего числа разнотипных символов в одном документе. Страница, которая создана на его основе, может содержать в себе буквы и иероглифы из разных языков (от русского до корейского) и математические знаки. При этом все символы в данной кодировке отображаются без проблем.
Причины создания
Когда-то, задолго до появления единой системы "Юникод", кодировка выбиралась исходя из предпочтений автора документа. По этой причине нередко, чтобы прочитать один документ, нужно было использовать разные таблицы. Иногда это приходилось делать по несколько раз, что существенно усложняло жизнь обычному пользователю. Как уже было сказано, решение этой проблемы в 1991 году было предложено некоммерческой организацией Unicode Inc., предложившей новый тип кодирования символов. Он был призван объединить морально устаревшие и разнообразные стандарты. "Юникод" - кодировка, которая озволила добиться немыслимого на тот момент: создать инструмент, поддерживающий огромное количество символов. Результат превзошел многие ожидания - появились документы, одновременно содержащие как английский, так и русский текст, латынь и математические выражения.
Но созданию единой кодировки предшествовала необходимость разрешения ряда проблем, которые возникли из-за огромного разнообразия стандартов, уже существовавших на тот момент. Самые распространённые из них:
- эльфийские письмена, или «кракозябры»;
- ограниченность набора символов;
- проблема преобразования кодировок;
- дублирование шрифтов.

Небольшой исторический экскурс
Представьте, что на дворе 80-е. Компьютерная техника еще не так распространена и имеет вид, отличный от сегодняшнего. В то время каждая ОС по-своему уникальна и доработана каждым энтузиастом под конкретные нужды. Необходимость обмена информацией превращается в дополнительную доработку всего на свете. Попытка прочитать документ, созданный под другой ОС, зачастую выводит на экран непонятный набор символов, и начинаются игры с кодировкой. Не всегда получается сделать это быстро, и порой необходимый документ удаётся открыть через полгода, а то и позже. Люди, которые часто обмениваются информацией, создают для себя таблицы преобразования. И вот работа над ними выявляет интересную деталь: создавать их нужно по двум направлениям: «из моей в твою» и обратно. Сделать банальную инверсию вычислений машина не может, для нее в правом столбце исходник, а в левом - результат, но никак не наоборот. Если появлялась необходимость использовать какие-либо специальные символы в документе, их необходимо было сначала добавить, а потом еще и объяснить партнеру, что ему нужно сделать, чтобы эти символы не превратились в «кракозябры». И не будем забывать, что под каждую кодировку приходилось разрабатывать или внедрять собственные шрифты, что приводило к созданию огромного количества дублей в ОС.
Представьте еще, что на странице шрифтов вы увидите 10 штук идентичных Times New Roman с маленькими пометками: для UTF-8, UTF-16, ANSI, UCS-2. Теперь вы понимаете, что разработка универсального стандарта была настоятельной необходимостью?

«Отцы-создатели»
Истоки создания Unicode следует искать в 1987 году, когда Джо Беккер из Xerox вместе с Ли Коллинзом и Марком Дэвисом из компании Apple начали исследования в сфере практического создания универсального набора символов. В августе 1988 года Джо Беккер опубликовал проект предложения по созданию 16-битной международной многоязычной системы кодирования.
Через несколько месяцев рабочая группа Unicode была расширена за счет включения Кена Уистлера и Майка Кернегана из RLG, Гленн Райт из Sun Microsystems и нескольких других специалистов, что позволило завершить работы по предварительному формированию единого стандарта кодирования.

Общее описание
В основе Unicode лежит понятие символа. Под этим определением понимается абстрактное явление, существующее в конкретном виде письменности и реализуемое через графемы (свои «портреты»). Каждый символ задается в "Юникоде" уникальным кодом, принадлежащим конкретному блоку стандарта. Например, графема B есть и в английском, и в русском алфавитах, но в Unicode ей соответствуют 2 разных символа. К ним применяется преобразование в т. е. каждый из них описывается ключом базы данных, набором свойств и полным названием.
Преимущества Unicode
От остальных современников кодировка "Юникод" отличалась огромным запасом знаков для «шифрования» символов. Дело в том, что его предшественники имели 8 бит, то есть поддерживали 28 символов, а вот новая разработка имела уже 216 символов, что стало гигантским шагом вперед. Это позволило закодировать практически все существующие и распространённые алфавиты.
С появлением "Юникода" отпала надобность использовать таблицы преобразования: как единый стандарт он просто сводил на нет их необходимость. Точно так же канули в Лету и «кракозябры» - единый стандарт сделал их невозможными, равно как и исключил необходимость создания дублей шрифтов.
Развитие Unicode
Конечно, прогресс не стоит на месте, и с момента первой презентации минуло уже 25 лет. Однако кодировка "Юникод" упрямо удерживает свои позиции в мире. Во многом это стало возможным благодаря тому, что он стал легко внедряемым и получил распространение, будучи признанным разработчикам проприетарного (платного) и открытого ПО.

При этом не стоит полагать, что сегодня нам доступна та же кодировка "Юникод", что и четверть века назад. На данный момент ее версия сменилась на 5.х.х, а количество кодируемых символов возросло до 231. От возможности использовать больший запас знаков отказались, чтобы всё еще сохранить поддержку для Unicode-16 (кодировки, где максимальное их количество ограничивалось цифрой 216). С момента своего появления и до версии 2.0.0 "Юникод-стандарт" увеличил количество символов, которые в него входили, практически в 2 раза. Рост возможностей продолжался и в последующие годы. К версии 4.0.0 уже появилась необходимость увеличить сам стандарт, что и было сделано. В результате "Юникод" обрел тот вид, в котором мы его знаем сегодня.

Что еще есть в Unicode?
Помимо огромного, постоянно пополняющегося количества символов, имеет еще одну полезную черту. Речь идет о так называемой нормализации. Вместо того чтобы пролистывать весь документ символ за символом и подставлять соответствующие значки из таблицы соответствия, используется один из существующих алгоритмов нормализации. О чем речь?
Вместо того чтобы тратить ресурсы вычислительной машины на регулярную проверку одного и того же символа, который может быть схожим в разных алфавитах, используется специальный алгоритм. Он позволяет вынести схожие символы отдельной графой таблицы подстановки и обращаться уже к ним, а не раз за разом перепроверять все данные.
Таких алгоритмов разработано и внедрено четыре. В каждом из них преобразование происходит по строго определенному принципу, отличающемуся от других, поэтому назвать какой-то один из них наиболее эффективным не представляется возможным. Каждый разрабатывался для определенных нужд, был внедрён и успешно используется.

Распространение стандарта
За 25 лет своей истории кодировка "Юникод" получила, вероятно, наибольшее распространение в мире. Под этот стандарт подгоняются также программы и web-страницы. О широте применения может говорить тот факт, что Unicode сегодня используют более 60 % интернет-ресурсов.
Теперь вам известно, когда появился стандарт "Юникод". Что это такое, вы также знаете и сможете оценить все значение изобретения, сделанного группой специалистов Unicode Inc. более 25 лет назад.
(коды от 0 до 127), т.е. одним байтом кодируются латинские буквы, цифры и специальные символы. Русские буквы (кириллица) представляются 16-битными (двухбайтными) кодами:
110XXXXX 10XXXXXX,
где X обозначены двоичные разряды для размещения кода символа в соответствии с таблицей UNICODE .
Юникод (англ. Unicode) - стандарт кодирования символов, позволяющий представить знаки почти всех письменных языков. Представляемые в юникоде символы кодируются целыми числами без знака. Эти числа будем называть кодами символов в юникоде или просто UNICODE . Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE) . (Англ. Unicode transformation format - UTF).
Рассмотрим, как кодируется в UTF-8 буква Ж . Её UNICODE - 1046 10 или 0416 16 или 10000 010110 2 . UNICODE в двоичном виде разбивается на две части: пять левых бит и шесть правых. Левая часть дополняется до байта признаком 110 двухбайтного кода UTF-8 : 110 10000. К правой части приписываются два бита 10 признака продолжения многобайтного кода: 10 010110. Окончательно код буквы Ж в UTF-8 выглядит так:
110
10000 10
010110 2
или D0 96 16
Таким образом, русская буква кодируется дважды: сначала в 11-битный UNICODE , а затем - в 16-битный UTF-8.
В приведённой ниже таблице, кроме кодов UNICODE и UTF-8 в шестнадцатиричной системе счисления, даны коды UTF-8 в десятичной системе счисления и для сравнения коды кириллицы в кодировке CP-1251 , иначе называемой windovs-1251 .
| Символ | UNICODE | UTF-8 | CP-1251 | ||
|---|---|---|---|---|---|
| Шестн. | Десят | Шестн. | Десят | ||
| А | 0410 | 1040 | D090 | 208 144 | 192 |
| Б | 0411 | 1041 | D091 | 208 145 | 193 |
| В | 0412 | 1042 | D092 | 208 146 | 194 |
| Г | 0413 | 1043 | D093 | 208 147 | 195 |
| Д | 0414 | 1044 | D094 | 208 148 | 196 |
| Е | 0415 | 1045 | D095 | 208 149 | 197 |
| Ж | 0416 | 1046 | D096 | 208 150 | 198 |
| З | 0417 | 1047 | D097 | 208 151 | 199 |
| И | 0418 | 1048 | D098 | 208 152 | 200 |
| Й | 0419 | 1049 | D099 | 208 153 | 201 |
| К | 041A | 1050 | D09A | 208 154 | 202 |
| Л | 041B | 1051 | D09B | 208 155 | 203 |
| М | 041C | 1052 | D09C | 208 156 | 204 |
| Н | 041D | 1053 | D09D | 208 157 | 205 |
| О | 041E | 1054 | D09E | 208 158 | 206 |
| П | 041F | 1055 | D09F | 208 159 | 207 |
| Р | 0420 | 1056 | D0A0 | 208 160 | 208 |
| С | 0421 | 1057 | D0A1 | 208 161 | 209 |
| Т | 0422 | 1058 | D0A2 | 208 162 | 210 |
| У | 0423 | 1059 | D0A3 | 208 163 | 211 |
| Ф | 0424 | 1060 | D0A4 | 208 164 | 212 |
| Х | 0425 | 1061 | D0A5 | 208 165 | 213 |
| Ц | 0426 | 1062 | D0A6 | 208 166 | 214 |
| Ч | 0427 | 1063 | D0A7 | 208 167 | 215 |
| Ш | 0428 | 1064 | D0A8 | 208 168 | 216 |
| Щ | 0429 | 1065 | D0A9 | 208 169 | 217 |
| Ъ | 042A | 1066 | D0AA | 208 170 | 218 |
| Ы | 042B | 1067 | D0AB | 208 171 | 219 |
| Ь | 042C | 1068 | D0AC | 208 172 | 220 |
| Э | 042D | 1069 | D0AD | 208 173 | 221 |
| Ю | 042E | 1070 | D0AE | 208 174 | 222 |
| Я | 042F | 1071 | D0AF | 208 175 | 223 |
| а | 0430 | 1072 | D0B0 | 208 176 | 224 |
| б | 0431 | 1073 | D0B1 | 208 177 | 225 |
| в | 0432 | 1074 | D0B2 | 208 178 | 226 |
| г | 0433 | 1075 | D0B3 | 208 179 | 227 |
| д | 0434 | 1076 | D0B4 | 208 180 | 228 |
| е | 0435 | 1077 | D0B5 | 208 181 | 229 |
| ж | 0436 | 1078 | D0B6 | 208 182 | 230 |
| з | 0437 | 1079 | D0B7 | 208 183 | 231 |
| и | 0438 | 1080 | D0B8 | 208 184 | 232 |
| й | 0439 | 1081 | D0B9 | 208 185 | 233 |
| к | 043A | 1082 | D0BA | 208 186 | 234 |
| л | 043B | 1083 | D0BB | 208 187 | 235 |
| м | 043C | 1084 | D0BC | 208 188 | 236 |
| н | 043D | 1085 | D0BD | 208 189 | 237 |
| о | 043E | 1086 | D0BE | 208 190 | 238 |
| п | 043F | 1087 | D0BF | 208 191 | 239 |
| р | 0440 | 1088 | D180 | 209 128 | 240 |
| с | 0441 | 1089 | D181 | 209 129 | 241 |
| т | 0442 | 1090 | D182 | 209 130 | 242 |
| у | 0443 | 1091 | D183 | 209 131 | 243 |
| ф | 0444 | 1092 | D184 | 209 132 | 244 |
| х | 0445 | 1093 | D185 | 209 133 | 245 |
| ц | 0446 | 1094 | D186 | 209 134 | 246 |
| ч | 0447 | 1095 | D187 | 209 135 | 247 |
| ш | 0448 | 1096 | D188 | 209 136 | 248 |
| щ | 0449 | 1097 | D189 | 209 137 | 249 |
| ъ | 044A | 1098 | D18A | 209 138 | 250 |
| ы | 044B | 1099 | D18B | 209 139 | 251 |
| ь | 044C | 1100 | D18C | 209 140 | 252 |
| э | 044D | 1101 | D18D | 209 141 | 253 |
| ю | 044E | 1102 | D18E | 209 142 | 254 |
| я | 044F | 1103 | D18F | 209 143 | 255 |
| Символы вне общего правила | |||||
| Ё | 0401 | 1025 | D001 | 208 101 | 168 |
| ё | 0451 | 1025 | D191 | 209 145 | 184 |
Иногда при написании поста возникает необходимость в символе (знаке), которого нет на клавиатуре, в таких ситуациях вам поможет таблица символов юникода. Сегодня мы рассмотрим онлайн сервис, в котором сгруппированы все символы юникода …
Таблица символов юникода
Для тех кому интересна предыстория появления Юникода - вот ссылка на википедию
Итак обозначим наши интересы в символах юникода
- это применение их в своих статьях, на своих сайтах.
Для начала перейдем на страницу сервиса Юникод символов
:
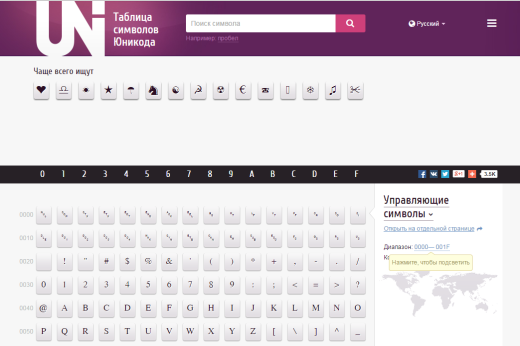
Давайте немого разберем интерфейс сего сервиса. В самом верху есть поле поиска, в нем достаточно вбить название искомого вами элемента, например: "Стрелка" или "Многоточие", после ввод нажмите на поиск, чтобы получить результат.
Рядом с поиском есть переключатель языка страницы.
Ниже идет перечень часто запрашиваемых символов, возможно среди них будет и нужный вам, если это так достаточно нажать на символ, чтобы перейти на страницу с детальной информацией о нем.
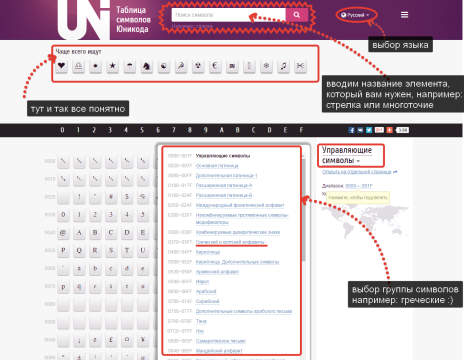
Основную часть страницы занимает таблица символов Юникода, для более удобного поиска вы также можете нажать на "Управляющие символы", чтобы выбрать группу символов, например: "Греческие символы", если вам нужно вставить символ греческого алфавита.
Поиск нужного элемента в таблице символов Юникода
Для примера воспользуемся поиском и введем в него слово "Стрелка" и нажмем поиск.

На странице результатов поиска ищем нужный нам символ и жмем на него для перехода на страницу детальной информации о нем.
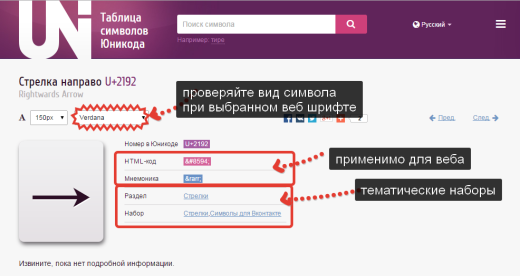
На странице Юникод символа нас интересует его HTML-код или код Мнемоники, оба можно использовать на веб-странице, для этого скопируйте код и вставьте его в нужном месте в HTML разметке, браузер интерпретирует его и на странице выведет как символ.
Обратите ваше внимание что на странице Юникод символа, есть возможность выбора шрифта. Всегда тестируйте как будет отображаться ваш шрифт при Verdana, Arial (и др. веб шрифтах) т.к. не все символы ими поддерживаются.
Ряд цифр и букв имеют внешне схожее начертание,
малоразличимое при небольшом размере шрифта.
Например, цифры "0", "1" и буквы
"О", "l" (L).
Это является серьёзной проблемой, особенно в тех случаях,
когда необходимо строго однозначное прочтение
символов. К примеру, при записи ручкой на листке бумаги
или печати на принтере своего буквенно-цифрового
пароля. Решением данной проблемы пришлось
заниматься первым программистам и
фонт-дизайнерам (в XX-м веке, в самом начале
компьютерной эры). Давно уже, появились
специальные контрастные шрифты, такие как
Inconsolata, Consolas (системный в OS Windows), Anonymous Pro, Deja Vu Sans Mono и многие другие.
Некоторые из них можно бесплатно скачать по ссылкам с
сайтов их авторов-создателей и с профильных Интернет-ресурсов.
Смотреть пример:
http://www.levien.com/type/myfonts/inconsolata.html
Если допускается техническими условиями и
проектным заданием, то вместо цифрового нуля, в
HTML-код ставится
"Ø" (latin capital letter O with stroke, с косым штрихом,
из модификации латинского алфавита для
скандинавских языков -
норвежского и датского), приблизительно похожий,
своим начертанием, на перечёркнутый пополам
нолик. В текстовом редакторе -
такой значок берётся, копируется из таблицы
спецсимволов (Special Character), и вставляется в нужную
позицию в строке. Данный
лайфхак-приём будет полезен, если возникают
сложности с поиском и установкой на девайс
специального фонта. Этот совет позволит
сэкономить время и не перепутать цифру "0"
(zero) с буквой "О" не только на мониторе вашего
ПК, но и на экранах других
устройств, где может не оказаться нужного шрифта.
Такая форма записи, традиционно, применяется при
обозначении на листе бумаги
смешанной, буквенно-цифровой информации,
например, своего пароля, кода доступа.
Примечательно, что даже есть шутливое выражение
" ", подчёркивающее важность
наличия этого элемента, наделяющего
символ определённым смыслом и значением.
Графический вид нуля в разных типах шрифтов -
можно посмотреть и сравнить их изображение на
картинках с помощью специализированного сервиса
на странице сайта:
http://www.fileformat.info/info/unicode/char/0030/fontsupport.htm
Рисунок 2
При редактировании и правке текста, перечёркивание неправильно написанного или ненужного символа - производится большим косым крестиком (двумя крест-накрест перекрещивающимися диагональными штрихами равной длины). В текстовом редакторе это осуществляется средствами форматирования - сначала выделяется фрагмент, а затем в меню нажимается последовательность кнопок и вкладок (Format - Character - Font Effects - Strikethrough) для выбора из выпадающих списков необходимого эффекта. Зачёркивание одного или нескольких слов в строчке или в целом абзаце документа - делается с помощью горизонтальной одинарной или двойной линии, достаточной толщины.
Если нужно точно выяснить, что в тексте написано - буква или цифра, то можно, в режиме поиска на странице, задать нужный символ и убедиться, что он будет найден именно там.