Статистический анализ и прогнозирование развития российского фондового рынка горбачев виктор викторович. Прогнозирование фондового рынка. История одного вечера темп прироста безналичной денежной массы
Ученые факультета вычислительной техники из исламского университета Азад, расположенного в ОАЭ, опубликовали работу , посвященную прогнозированию поведения фондовых индексов на основе технологий нейронных сетей, генетических алгоритмов и data mining с использованием опорных векторов. Мы представляем вашему вниманию главные мысли этого документа.
Введение
Одним из популярных направлений финансово анализа в последние годы является прогнозирование цен акций и поведения фондовых индексов на основе данных о предыдущих торговых периодах. Для получения сколько-нибудь релевантных результатов необходимо использование подходящих инструментов и корректных алгоритмов.Ученые поставили своей целью разработку специального софта, который бы мог генерировать прогнозы поведения фондовых индексов с помощью предиктивных алгоритмов и математических правил.
Фондовые индексы сами по себе непредсказуемы, поскольку зависят не только от экономических событий, но на них также влияет и политическая обстановка в разных частях света. Поэтому разработать математическую модель для обработки таких непредсказуемых, нелинейных и непараметрических временных рядов крайне сложно.
При работе на фондовом рынке используют два вида анализа.
1) Технический анализ
Применяется для краткосрочных финансовых стратегий. Он используется для прогнозирования изменения цен на основе закономерностей и изменении цен схожим образом в прошлом. Как правило, анализируются графики цен, на которых выделяются паттерны определенных закономерности в ценовой динамике. Помимо изучения динамики изменения цены, в техническом анализе используется информация об объёмах торгов и другие статистические данные.
2) Фундаментальный анализ
Для долгосрочных стратегий инвестирования используется фундаментальный анализ. Он подразумевает использования для прогнозирования цены акций определенной компании, информацию о финансовых и прозводственных показателях ее деятельности.
Также, при прогнозировании возможных движений цен необходимо понимать существующие на финансовом рынке риски для действующих на нем игроков:
- Торговый риск - объём средств, которым рискует трейдер. К примеру, если он покупает финансовый актив на тысячу долларов, то торговый риск будет равняться этой сумме.
- Рыночный риск - что может случиться на рынке под влиянием в том числе глобальных экономических событий или событий в конкретной стране, где расположен финансовый рынок или акции компаний из которой торгуются на бирже.
- Маржинальный риск - если для совершения сделок используются заемные средства, возникает маржинальный риск. Взятые «в долг», к примеру, у брокера, деньги в конечном итоге придется вернуть, и если у трейдера будет недостаточно свободных средств на счете для этого, то его позиции будут принудительно закрыты даже если это не подразумевалось его торговой стратегией.
- Риск ликвидности - не из каждого финансового инструмента можно быстро «выйти».
- Риск переноса позиций «овернайт» - сохранение позиций в промежуток между торговыми днями или на протяжении нескольких торговых дней несет в себе риск, поскольку трейдер не может знать, что случится в то время, когда биржа не работает. Возможно на открытие торгового дня повлияет какое-то событие, и цена акций сразу сместится невыгодным для инвестора образом.
- Риск волатильности - цена акций колеблется в определенных диапазонах. Чем шире диапазон колебания цены, тем выше волатильность конкретного финансового инструмента.
Прогнозирование поведения фондовых индексов
Одним из популярных инструментов, использующихся для решения задач прогнозирования цен акций, является дерево принятия решений. В свою очередь, наиболее эффективным методом сбора и анализа данных является data mining. Существует несколько моделей использования data mining, которые реализуют различные подходы к сбору и анализу полученной информации.В нашем случае исследователи выбрали модель CRISP-DM (Cross-Identity Standard Process for Data Mining). Данный метод был разработан консорциумом европейских компаний в середине девяностых годов прошлого века. Модель включает семь основных шагов:
- Определение целей для поиска информации (данные о каких акциях нужны).
- Поиск нужных данных.
- Упорядочивание данных в модели классификации.
- Выбор техники для реализации модели.
- Оценка модели с помощью известных методов.
- Применение модели в текущих рыночных условиях для генерации рекомендации о целевом действии - к примеру, покупка или продажа акции.
- Оценка полученных результатов.
Также для прогнозирования используются генетические алгоритмы. Они применяются для решения сложных проблем, в тех случаях, когда точные отношения между задействованными элементами неизвестны и могут в принципе отсутствовать.
Задача формализуется так, чтобы ее решение могло был закодировано в виде вектора генов («генотип»), где каждый ген может представлять бит, число или какой-либо другой объект. Далее случайным образом создается множество генотипов начальной «популяции», которые оцениваются с помощью специальной функции приспособленности. В итоге каждому генотипу присваивается значение «приспособленности» - именно оно определяет, насколько хорошо он решает задачу.
Для постоянной оптимизации параметров, задействованных в торговой стратегии, используются методы оптимизации. К примеру, ген может быть представлен в виде вектора, а соответствующий алгоритм оптимизации применяет к нему механизм промежуточной рекомбинации.
Одним из методов генерирования предсказаний о будущих движениях цен является машинное обучение. В данном случае исследователи использовали метод опорных векторов. Исследователи собрали финансовые данные с биржи NASDAQ, а также о некоторых финансовых инструментах и индексах. В резульате для NASDAQ точность предсказаний, сгенерированных системой, составила 74.4%, 77,6% для индекса DJIA и 76% для S&P500.
Для машинного обучения использовались следующие формулы:
Прежде всего, определялось x i (t), где i ∈ {1, 2, …}.
F = (X 1 , X 2 , … X n) T , где

Для оценки используемой модели использовался метод вычисления среднеквадратичной ошибки (RMSE, Root of Mean Square Error):
Мультиклассовая классификация
Для минимизации рисков и повышения прибыли используется модель опорных векторов. Она подразумевает классификацию данных в три категорий: позитивную, негативную и нейтральную. Это помогает выявлять наиболее рискованные прогнозы и отклонять их. Для создания такого мультиклассового классификатора, неободимо определить ширину центральной зоны:
tp: true positive
fp: false positive
fn: false negative
Предложенная модель
Как было отмечено выше, собираемые данные имели шесть атрибутов. Для использования в дереве принятия решений данные должны быть конвертированы в дискретные значения. Для этого можно использовать критерий, основанный на цене закрытия рынка. В случае, если величина open, max, min и last превышает предыдущее значение атрибута в ходе текущего торгового дня, то позитивное значение должно быть заменено на предыдущий атрибут. Напротив, негативное значение устанавливается вместо предыдущего атрибута, а если значения равны, то устанавливается соответствующий атрибут.Вот так выглядит набор данных по шести атрибутам до их перевода в дискретные значения:

А вот так после перевода:

После получения такого набора дискретных значений необходимо построить модель классификации с помощью дерева принятия решения.
В данном исследовании рассматривается два возможных сценария действий.
Сценарий #1
Необходимо проделать следующие действия:- Собрать финансовые данные о торгах за 30 дней.
- Выделить данные по шести атрибутам в 9 моментов времени в течение одного торгового дня.
- Для каждого набора сформировать матрицу.
- Вычислить XX^T и применить метод опорных векторов для генерирования собственного значения.
- Вычисление среднего объёма продаж и покупок.
- Вычисление среднего значения каждого торгового дня.
- Присвоение разных весов для первого дня, седьмого и тридцатого дня, а также среднего значения месяца.
- Для генерирования рекомендации о действии необходимо сравнить текущее значение с первым, седьмым, тридцатым днем, а также средним значением за весь месяц.
- Если результат предсказания за 4 торговых дня одинаковый, то следует осуществить покупку, если присутствует совпадение для трех торговых дней, то покупка будет иметь риск в 25%, для двух дней риск составит 50%.

После этого вычисляется R = XX T - каждую матрицу нужно умножить на транспонированную версию. Затем подсчитывается опорный вектор и его собственное значение.
Сценарий 2
В данном случае выполняются все те же шаги, однако метод опорных векторов применяется не к «сырым» данным, а к матрице, полученной после автокорреляции. Для каждого торгового дня генерируется матрица автокорреляции:
Здесь используется следующая формула:

После автокорреляции мы получаем новую матрицу (матрицу Теплица):

И уже для нее подсчитывается опорный вектор и собственное значение. Для сравнения отклонения от среднего значения среди различных торговых дней, вычисляется среднее значение, дисперсия и стандартное отклонение, которые хранятся в векторе.
Заключение
Для получения наилучших результатов исследователи применили все описанные методы шаг за шагом: начиная с фундаментального анализа, использования генетического алгоритма, нейронных сетей, машинного обучения и метода опорных векторов.
При этом добиться стопроцентной точности прогнозов изменения значений фондовых индексов добиться не удалось. Для различных финансовых инструментов точность предсказания поведения индексов на промежутке в один торговый день довольно сильно отличается:

Наилучшим результатом стала точность в 70,8% для немецкого индекса DAX. Для достижения большей точности при долгосрочных прогнозах (период больше 30 дней), использовалась следующая формула:
Pr {v t+1 – v t > c t }, где c t = -(v t-ts – v t)
В этом случае наилучший результат точности прогноза составил 85,0%.
Благодаря стремительному развитию информационных технологий, появилась возможность за считанные секунды проводить анализ большого объёма информации, строить сложные математические модели, решать задачи многокритериальной оптимизации. Учёные, занимающиеся вопросами циклического развития экономики, стали разрабатывать теории, полагая, что отслеживание тенденций ряда экономических переменных позволит прояснить и предсказать периоды подъёма и спада. Одним из объектов для изучения был выбран фондовый рынок. Предпринимались многократные попытки построить такую математическую модель, которая успешно бы решала задачу прогнозирования приращения цены акций. В частности, широкое распространение получил «технический анализ».
Технический анализ
(тех. анализ) – это совокупность методик исследования динамики рынка, чаще всего посредством графиков, с целью прогнозирования будущего направления движения цен. На сегодняшний день, данный аналитический метод является одним из самых популярных. Но можно ли считать тех. анализ пригодным для генерации прибыли? Для начала рассмотрим теории ценообразования на фондовом рынке.
Одной из базовых концепций начиная с 1960-х гг. считается гипотеза эффективного рынка (efficient market hypothesis, EMH), согласно которой, информация о ценах и объёмах купли-продажи за прошедший период общедоступна. Следовательно, любые данные, которые можно было когда-либо извлечь из анализа прошлых котировок, уже нашли своё отражение в цене акций. Когда трейдеры конкурируют между собой за более успешное использование этих общедоступных знаний, они обязательно приводят цены к уровням, при которых ожидаемые ставки доходности полностью соответствуют риску. На этих уровнях невозможно говорить о том, является ли покупка акций хорошей или плохой сделкой, т.е. текущая цена объективна, а это означает, что ожидать получения сверх рыночной доходности не приходится. Таким образом, на эффективном рынке, цены активов отражают их истинные стоимости, а проведение тех. анализа теряет всяческий смысл.
Но следует отметить тот факт, что на сегодняшний день ни один из существующих фондовых рынков в мире не может быть назван полностью информационно эффективным. Более того, принимая во внимание современные эмпирические исследования, можно сделать вывод, что теория эффективного рынка является скорее утопией, т.к. не способна в полной мере рационально объяснить реальные процессы, протекающие на финансовых рынках.

В частности, профессором Йельского университета Робертом Шиллером был обнаружен феномен, который он в последующем назвал чрезмерной изменчивостью цен фондовых активов. Суть феномена заключается в частом изменении котировок, которое не поддаётся рациональному объяснению, а именно, отсутствует возможность интерпретировать данное явление соответствующими изменениями в фундаментальных факторах .
В конце 1980-х гг. были сделаны первые шаги к созданию модели, которая в отличие от концепции эффективного рынка, позволила бы точнее объяснить реальное поведение фондовых рынков. В 1986 г. Фишер Блэк в своей публикации вводит новый термин – «шумовая торговля».

«Шумовая торговля – это торговля на шуме, воспринимаемом так, как если бы шум был бы информацией. Люди, торгующие на шуме, будут торговать даже тогда, когда объективно они должны были бы воздерживаться от этого. Возможно, они считают, что шум, на основе которого они торгуют, является информацией. Или, возможно, им просто нравится торговать ». Хотя Ф. Блэк не указывает, каких операторов следует относить к категории «шумовых трейдеров», в работе Де Лонга, Шляйфера, Саммерса и Вальдмана можно найти описание таких участников рынка. Шумовые трейдеры ошибочно полагают, что у них есть уникальная информация о будущих ценах на активы. Источниками такой информации могут быть ложные сигналы о несуществующих трендах, подаваемые индикаторами тех. анализа, слухи, рекомендации финансовых «гуру». Шумовые трейдеры сильно переоценивают значение имеющейся информации и готовы принимать на себя необоснованно большой риск. Проведённые эмпирические исследования также указывают на то, что к шумовым трейдерам в первую очередь следует отнести индивидуальных инвесторов, т.е. физических лиц. Более того, именно эта группа трейдеров несёт систематические убытки от торговли из-за иррациональности своих действий. Для западных фондовых рынков эмпирическое подтверждение этого явления можно найти в исследованиях Барбера и Одина, а для операторов российского фондового рынка – в работе И.С. Нилова. Теория шумовой торговли позволяет объяснить и феномен Р. Шиллера. Именно иррациональные действия трейдеров вызывают чрезмерную изменчивость цен.
Обобщая современные исследования в области теорий ценообразования на фондовом рынке, можно сделать вывод о неэффективности использования технического анализа для получения прибыли. Более того, трейдеры, использующие тех. анализ пытаются выделять повторяющиеся графические паттерны (от англ. pattern - модель, образец). Стремление найти различные модели поведения цен является очень сильным, а способность человеческого глаза выделять очевидные тренды удивительна. Однако выделенные закономерности могут вовсе не существовать. На графике представлены смоделированные и фактические данные индекса Dow Jones Industrial Average на протяжении 1956 года, взятые из исследования Гарри Робертса.

График (B) представляет собой классическую модель «голова-плечи». График (А) также выглядит как «типичная» схема поведения рынка. Какой из двух графиков построен на основе фактических значений биржевого индекса, а какой – с помощью смоделированных данных? График (А) построен на основе фактических данных. График (B) создан с помощью значений, выданных генератором случайных чисел. Проблема, связанная с выявлением моделей там, где их на самом деле не существует, заключается в отсутствии необходимых данных. Анализируя предыдущую динамику, всегда можно выявить схемы и методы торговли, которые могли дать прибыль. Иными словами, существует совокупность бесконечного количества стратегий основанных на тех. анализе. Часть стратегий из общей совокупности демонстрируют на исторических данных положительный результат, другие – отрицательный. Но в будущем, мы не можем знать, какая группа систем позволит стабильно получать прибыль.
Также, одним из способов определения наличия закономерностей во временных рядах, является измерение сериальной корреляции . Существование сериальной корреляции в котировках, может свидетельствовать об определенной взаимосвязи между прошлой и текущей доходностью акций. Положительная сериальная корреляция означает, что положительные ставки доходности, как правило, сопровождаются положительными ставками (свойство инерционности). Отрицательная сериальная корреляция означает, что положительные ставки доходности, сопровождаются отрицательными ставками (свойство реверсии или свойство «коррекции»). Применяя данный метод к биржевым котировкам, Кендалл и Робертс (Kendall and Roberts, 1959), доказали, что закономерностей обнаружить не удаётся.
Наряду с техническим анализом, достаточно широкое распространение получил фундаментальный анализ . Его цель – анализ стоимости акций, опирающийся на такие факторы, как перспективы получения прибыли и дивидендов, ожидания будущих процентных ставок и риск фирмы. Но, как и в случае технического анализа, если все аналитики полагаются на общедоступную информацию о прибылях компании и её положении в отрасли, то трудно ожидать, что оценка перспектив, полученная каким-то одним аналитиком, намного точнее оценок других специалистов. Подобные исследования рынка выполняются множеством хорошо информированных и щедро финансируемых фирм. Учитывая столь жёсткую конкуренцию, трудно отыскать данные, которыми ещё не располагают другие аналитики. Следовательно, если информация о конкретной компании общедоступна, то ставка доходности, на которую сможет рассчитывать инвестор, будет самой обычной.
Помимо вышеописанных методов, для прогнозирования рынка пытаются применять нейронные сети, генетические алгоритмы и т.д. Но попытка использовать прогностические методы применительно к финансовым рынкам превращает их в самоликвидирующиеся модели . Например, предположим, что с помощью одного из методов спрогнозирована базовая тенденция роста рынка. Если теория широко признана, многие инвесторы сразу же начнут скупать акции в ожидании роста цен. В результате, рост окажется намного резче и стремительнее, чем это предсказывалось. Или же рост может вообще не состояться из-за того, что крупный институциональный участник, обнаружив чрезмерную ликвидность, начнёт распродавать свои активы.
Самоликвидация прогностических моделей возникает из-за применения их в конкурентной среде, а именно в среде, в которой каждый агент старается извлечь собственную выгоду, определённым образом влияя на систему в целом. Влияние отдельного агента на всю систему не значительно (на достаточно развитом рынке), однако наличие эффекта суперпозиции провоцирует самоликвидацию конкретной модели. Т.е. если в основе торгового алгоритма лежат прогностические методы, стратегия приобретает свойство неустойчивости, а в долгосрочной перспективе происходит самоликвидация модели. Если же стратегия является параметрической и прогностически нейтральной, то это обеспечивает конкурентное преимущество по сравнению с торговыми системами, в которых для принятия решения используется прогноз. Но стоит учитывать, что поиск стратегий, удовлетворяющих таким параметрам как, например, прибыль/риск происходит одновременно с поиском подобных систем другими трейдерами и крупными финансовыми компаниями на основе одних и тех же исторических данных и практически по одним и тем же критериям. Из этого следует необходимость использовать системы, основанные не только на общепринятых основных параметрах, но и на таких показателях, как надежность, стабильность, живучесть, гетероскедастичность и т. д. Особый интерес представляют торговые стратегии, базирующиеся на так называемых «дополнительных информационных измерениях» . Они проявляются в других, обычно смежных областях деятельности и по разным причинам редко используются широким кругом лиц на рынке акций.
Вышеизложенные рассуждения позволяют сделать следующие выводы:
- Теория шумовой торговли, в отличие от концепции эффективного рынка, позволяет более точно объяснить реальное поведение фондовых активов.
- В изменениях котировок торговых инструментов отсутствует закономерность, т.е. рынок предсказать невозможно.
- Применение прогностических методов, в частности технического анализа, приводит к неизбежному разорению трейдера в среднесрочной перспективе.
- Для успешной торговли на фондовом рынке, необходимо применять прогностически нейтральные стратегии, базирующиеся на «дополнительных информационных измерениях».
Список использованной литературы:
- Shiller R. Irrational Exuberance. Princeton: Princeton University Press, 2000.
- Black F. Noise // Journal of Finance. 1986. Vol. 41. Р. 529-543.
- De Long J. B., Shleifer A. M., Summers L. H., Waldmann R. J. Noise Trader Risk in Financial Markets // Journal of Political Economy. 1990. Vol. 98. Р. 703-738.
- Barber B. M., Odean T. Trading is hazardous to your wealth: The common stock investment performance of individual investors // Journal of Finance. 2000. Vol. 55. № 2. P. 773-806.
- Barber B. M., Odean T. Boys will be boys: Gender, overconfidence, and common stock investment // Quarterly Journal of Economics. 2001. Vol. 116. Р. 261-292.
- Odean T. Do investors trade too much? // American Economic Review. 1999. Vol. 89. Р. 1279-1298.
- Нилов И. С. Кто теряет свои деньги при торговле на фондовом рынке? // Финансовый менеджмент. 2006. № 4.
- Нилов И. С. Шумовая торговля. Современные эмпирические исследования // РЦБ. 2006. № 24.
- Harry Roberts. Stock Market Patterns and Financial Analysis: Methodological Suggestions // Journal of Finance. Marth 1959. P. 5-6.
Курс ценных бумаг на фондовой бирже складывается из двух факторов: реальная стоимость капитала компании (ее перспективы) и соотношение спроса и предложения. С одной стороны, чем лучше обстоят дела у организации-эмитента, тем выше доходность ее ценных бумаг и тем ниже риск, что обуславливает повышение курса. С другой стороны, действует простой закон рынка: чем выше спрос на ценные бумаги, тем дороже они стоят.
Эти факторы могут иметь разную направленность. Так, компания может процветать, а ее акции - дешеветь из-за слишком высокого предложения и низкого спроса.
Первый фактор, учитывающий текущее и будущее финансовое состояние компании и отрасли, лежит в основе фундаментального анализа фондового рынка. Второй, при котором оценивают только движение курса ценных бумаг, используют при техническом анализе . Эти методы прогнозирования фондового рынка позволяют предсказать движение курсов ценных бумаг в краткосрочной или долгосрочной перспективе.
Технический анализ фондового рынка
Тех. анализ фондового рынка появился еще в XVIII-XIX веках (так называемые «японские свечи»). В прошлом, когда у инвесторов не было доступа к информации о финансовом положении компании, им оставалось ориентироваться на внешние показатели (прежде всего, динамику курса). Метод позволяет предсказать значительное повышение и снижение цены в краткосрочной перспективе, но не охватывает все факторы, способные повлиять на курс.
В арсенале у аналитика – только графики котировок активов. На их основе работают и программы для технического анализа фондового рынка. Самая популярная программа - MetaStock. Некоторые брокеры и площадки разрабатывают свой софт.
Технический анализ рынка акций в России и мире основан на трех принципах:
1. Текущая цена складывается из всех факторов, способных на нее повлиять (состояние компании, отрасли, рынка и т. д.), а значит, трейдеру не нужно их изучать.
3. Все повторяется. На цену влияют психологические факторы, как и в далеком прошлом, а на рынке могут преобладать либо бычьи, либо медвежьи, либо нейтральные тренды.
Особенности фундаментального анализа рынка акций
Распространение фундаментального анализа обязано двум предпосылкам. Первая - отсутствие точности у тех. анализа фондового рынка. При оценке котировок трейдер не всегда правильно отслеживает тренд, а в отношении начинающих компаний-эмитентов это и вовсе невозможно: у из акций нет динамики.
Вторая предпосылка - появление новых правил на фондовых биржах. С недавних пор эмитенты, выпускающие ценные бумаги, обязаны публиковать финансовую отчетность. Именно ее анализируют инвесторы, принимая решение в пользу тех или иных акций.
Задача инвестора - определить реальную цену активов и спрогнозировать ее движение в будущем. Аналитик оценивает состояние самой компании в контексте отрасли и всего рынка и выявляет недооцененные и переоцененные ценные бумаги.
Торговля ценными бумагами на фондовом рынке предполагает прогнозирование котировок с целью выявления наиболее интересных с точки зрения стоимости акций (индексов) для покупки. Здесь не обойтись без аналитических методов. Одним из наиболее интересных и полезных является именно фундаментальный анализ. Этот цикл статей посвящен данному типу прогнозирования.
Фундаментальный анализ фондового рынка – это оценка ценных бумаг на нескольких уровнях (макроэкономический, анализ направлений, анализ конкретной компании). Очень важно понимать, что данный метод исследует тенденции и работает исключительно в среднесрочной и долгосрочной перспективе.
Некоторые трейдеры ошибочно полагают, что фундаментальный анализ фондового рынка сводится исключительно к статистическому срезу. То есть они пытаются торговать по одной отдельной новости, полагая, что тем самым, обращаются к фундаментальному анализу. Но эта методика определяется, как работа на новостях и лишь отчасти относится к фундаментальной. Далее мы разберем основные уровни, с помощью которых можно прогнозировать котировки.
Макроэкономический уровень анализа фондового рынка
Фундаментальный анализ фондового рынка следует начинать с экономического прогнозирования. Деятельность той или иной компании очень тесно связана как с экономикой отдельного государства, так и с мировой экономикой в целом.
В целом, если ситуация в экономике стабильная и наблюдается рост, можно сказать, что и отдельные предприятия также будут расти. С другой стороны, если в экономике наблюдаются проблемы, то и компании вряд ли будут существенно развиваться. Но это в целом. На самом деле все зависит от сферы работы предприятия. К примеру, IT-компании даже в период кризиса могут продолжать развиваться.
Для оценки экономического состояния государства используют набор , которые публикуются в календарях статистики. На сегодняшний день, таких календарей очень много. В них собраны все основные показатели, которые позволяют оценить положение дел в экономике и сделать соответствующие выводы.
Большое влияние на котировки фондового рынка оказывает монетарная политика, проводимая центральными банками. В наших последующих статьях мы продемонстрируем на конкретных примерах влияние программ, известных как «Количественное смягчение» на колебания котировок.
Основные направления, на которые следует обратить внимание в процессе анализа:
- динамика ВВП;
- показатели занятости;
- динамика деловой активности;
- потребительский спрос;
- решения центральных банков.
Все эти показатели в целом отражают состояние экономики отдельных государств. Увеличение темпов роста ВВП говорит о том, что экономика продолжает развиваться. И это может указывать на будущий рост стоимости акций.
Анализ направлений фондового рынка
Для того, чтобы продолжить прогнозирование котировок, необходимо обратиться к анализу и поиску перспективных направлений в экономике, которые будут развиваться в будущем. Это средний уровень оценки фондового рынка.
С одной стороны, такая работа кажется сложной. Но на самом деле, здесь не должно возникать никаких проблем, если трейдер сможет найти необходимую информацию и приложит должные усилия для ее анализа.
- В периоды экономического роста, большинство сфер будет процветать. Это касается как компаний, работающих с сырьем, так и предприятий, которые занимаются производством товаров и услуг, а также различными разработками.
- В периоды рецессий или стагнаций, можно наблюдать обратную картину – деловая активность снижается. Как результат, многие сферы экономики демонстрируют отрицательную динамику. К примеру, на фоне глобальных проблем в экономике существенно страдает сырьевой сектор (так как снижение экономической активности ведет к снижению потребления сырья).
Помощь в анализе направлений оказывают всевозможные индексы фондовых бирж. К примеру, Dow Jones Industrial Average демонстрирует ситуацию в промышленном секторе США. Dow Jones Transportation Average показывает динамику в транспортном секторе. Если вы планируете покупать акции в этих направлениях, анализируя котировки данных индексов, можно увидеть общую тенденцию.
Фундаментальный анализ компаний фондового рынка
 Это третий уровень фундаментального анализа фондового рынка. Здесь трейдеру необходимо и приобрести их по как можно меньшей стоимости для того, чтобы в будущем продать их подороже.
Это третий уровень фундаментального анализа фондового рынка. Здесь трейдеру необходимо и приобрести их по как можно меньшей стоимости для того, чтобы в будущем продать их подороже.
С этой целью могут использоваться следующие показатели:
- рейтинги от различных организаций;
- рекомендации аналитиков;
- новости компании (слияния, поглощения, капитализация);
- выпуск или выкуп акций;
- получение государственных заказов.
Новости компаний также могут оказывать влияние на колебания котировок фондового рынка. К примеру, если одна компания поглощает другую, то у первой акции будут падать (это связано с дополнительными финансовыми расходами). В то же самое время, покупаемая компания может вырасти в цене на фондовом рынке (так как ожидаются финансовые вливания в нее).
Выпуск новых акций говорит о привлечении дополнительных инвестиций. Это хороший знак для покупателей. То же самое касается выкупа своих акций компаниями.
Наконец, если фирма получает государственный заказ, ее акции также могут расти в цене. Дело в том, объемы таких заказов обычно очень существенны. Следовательно, компания получит хорошую прибыль и, возможно, расширит свои мощности. Вся эта информация поступает после в отдельности.
Проанализировав все три уровня, исследуя фундаментальный анализ фондового рынка, трейдер сможет понять, каковы перспективы у того или иного актива. Обладая подобной информацией, он сможет принимать грамотные решения.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter .
Прогнозирование фондового рынка - это заманчивый «философский камень» для специалистов по анализу данных, которые мотивированы не столько стремлением к материальной выгоде, сколько самой задачей. Ежедневный рост и падение рынка наводят на мысль, что должны быть закономерности, которым мы или наши модели могут научиться , чтобы победить всех этих трейдеров с научными степенями по бизнесу.
Когда я начал использовать аддитивные модели для прогнозирования временных рядов, я протестировал метод на эмуляторе фондового рынка с имитируемыми (ненастоящими) акциями. Неизбежно я присоединился к другим несчастным, которые ежедневно терпят неудачу на рынке. Тем не менее, в процессе я узнал массу нового о Python, включая объектно-ориентированное программирование, манипулирование данными, построение моделей и визуализацию . Также выяснилось, почему не стоит рассчитывать на ежедневную рыночную игру без потери единой копейки (все, что я могу сказать — играть нужно долгосрочно)!
Один день против 30 лет: во что бы вы вложили свои деньги?
В любой задаче, не только в Data science, если не удалось достичь желаемого, есть три варианта:
- Изменить результаты так, чтобы они выглядели в выгодном свете;
- Скрыть результаты — никто не заметит провала;
- Показать результаты и методы всем, чтобы люди могли чему-то научиться и, возможно, предложить улучшения.
В то время как третий вариант - оптимальный выбор на индивидуальном и общественном уровне, он требует наибольшего мужества. Ведь я могу специально демонстировать особые случаи, когда моя модель приносит прибыль. Или можно притвориться, что я не потратил десятки часов на работу, и просто выбросить её. Как глупо! На самом деле, только неоднократно потерпев неудачу и допустив сотню ошибок, мы двигаемся вперед. Более того, код Python, написанный для такой сложной задачи, не может быть написан напрасно!
Этот пост документирует возможности Stocker, инструмента прогнозирования рынка, разработанного мной на Python. я показал, как использовать Stocker для анализа, а для тех, кто хочет опробовать его самостоятельно или внести свой вклад в проект, полный код доступен на GitHub .
Stocker для прогнозирования
Stocker - инструмент Python для прогнозирования рынка. Как только будут установлены необходимые библиотеки (см. документацию), можно запустить Jupyter Notebook в той же папке, что и скрипт, и импортировать класс Stocker:
From stocker import Stocker
Класс теперь доступен для сеанса Jupyter. Создадим объект класса Stocker, передавая ему любой действительный тикер, например, ‘AMZN’ (вывод программы выделен жирным шрифтом):
Amazon = Stocker("AMZN") AMZN Stocker Initialized. Data covers 1997-05-16 to 2018-01-18.
Теперь к нам в распоряжение попали 20 лет ежедневных данных по акциям Amazon для исследований! Stocker построен на финансовой библиотеке Quandl и содержит более 3000 курсов акций для использования. Построим простой график курса, вызывая метод plot_stock:
Amazon.plot_stock() Maximum Adj. Close = 1305.20 on 2018-01-12. Minimum Adj. Close = 1.40 on 1997-05-22. Current Adj. Close = 1293.32.

Stocker применяют для обнаружения и анализа общих трендов и закономерностей, но сейчас сосредоточимся на прогнозировании будущей цены. Предсказания в Stocker производятся с использованием , которая рассматривает временные ряды как комбинацию тренда и сезонных изменений в разных временных масштабах (ежедневный, еженедельный и ежемесячный). Stocker использует «предсказательный» пакет, разработанный Facebook для аддитивного моделирования. Создание модели и прогнозирование можно выполнить в Stocker одной строкой:
# предсказать на дни вперед model, model_data = amazon.create_prophet_model(days=90) Predicted Price on 2018-04-18 = $1336.98
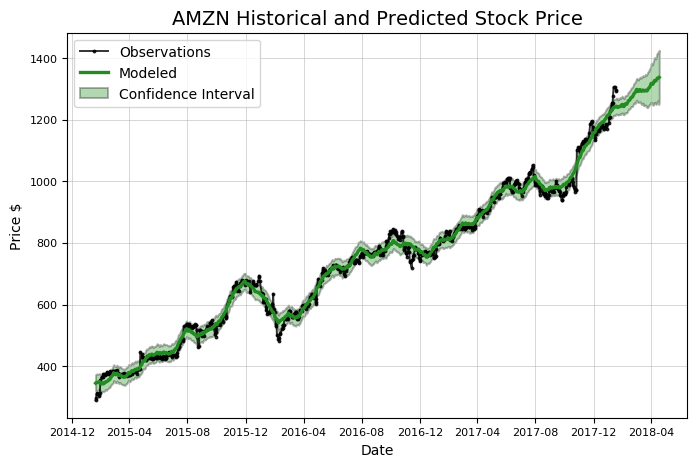
Обратите внимание, что прогноз (зеленая линия) содержит доверительный интервал. Он отражает «неуверенность» модели в предсказании. В данном случае ширина доверительного интервала устанавливается с уровнем доверия 80%. Доверительным называют интервал, который покрывает неизвестный параметр с заданной надёжностью. Он расширяется с течением времени, потому что оценка имеет большую неопределенность по мере того, как она удаляется от имеющихся данных. Каждый раз, делая прогноз, следует включать этот доверительный интервал. Хотя большинство людей, как правило, хотят получить простой численный ответ, прогноз отражает то, что мы живем в неопределенном мире!
Дать предсказание нетрудно: достаточно выбрать некоторое число, и это будет предположением о будущем (возможно, я ошибаюсь, но это всё, что делают люди с Уолл-стрит). Но этого мало. Чтобы доверять модели, нужно оценить ее точность. Для этого в Stocker существует ряд методов.
Оценка прогнозов
Чтобы вычислить точность прогнозов, нам нужен обучающий и тестовый наборы данных. Для тестового набора необходимо знать ответы - фактическую цену акций, поэтому мы будем использовать данные курса за прошлый год (2017, в нашем случае). Во время обучения мы не позволим модели видеть ответы тестового набора, поэтому используем наблюдения за предшествующие три года (2014-2016). Основная идея обучения с учителем (supervised learning) заключается в том, что модель изучает закономерности и отношения в данных из обучающего набора, а затем умеет правильно воспроизводить их на тестовой выборке.
Чтобы количественно оценить точность, на основе предсказанных и фактических значений вычисляются следующие показатели:
- средняя численная ошибка в долларах на тестовом и обучающем наборе;
- процент времени, когда мы правильно предсказали направление изменения цены;
- процент времени, когда фактическая цена попала в пределы прогнозируемого доверительного интервала в 80%.
Все вычисления автоматически выполняются Stocker с приятным визуальным сопровождением:
Amazon.evaluate_prediction() Prediction Range: 2017-01-18 to 2018-01-18. Predicted price on 2018-01-17 = $814.77. Actual price on 2018-01-17 = $1295.00. Average Absolute Error on Training Data = $18.21. Average Absolute Error on Testing Data = $183.86. When the model predicted an increase, the price increased 57.66% of the time. When the model predicted a decrease, the price decreased 44.64% of the time. The actual value was within the 80% confidence interval 20.00% of the time.

Это ужасная статистика! С таким же успехом можно каждый раз подбрасывать монету. Если бы мы руководствовались полученными результатами для инвестиций, нам разумней было бы вложиться в лотерейные билеты. Однако пока не будем отказываться от модели. Изначально она ожидаемо будет довольно плохой, потому что использует некоторые настройки по умолчанию (называемые гиперпараметрами).
Если наши первоначальные попытки не увенчались успехом, мы можем нажимать эти своеобразные рычаги и кнопки, чтобы заставить модель работать лучше. В Prophet можно настроить множество параметров, причем наиболее важным является коэффициент масштаба распределения весов для контрольных точек (changepoint prior scale). Он отвечает за набор весов, который накладывается на развороты и флуктуации тренда.
Настройка выбора контрольных точек
Контрольные точки (changepoints) - это места, где временные ряды значительно меняют направление или скорость изменения цены (от медленно возрастающего до все более быстрого или наоборот). Коэффициент масштаба распределения весов для контрольных точек (changepoint prior scale) отражает количество «уделенного внимания» точкам изменения курса акций. Это используется для контроля над недообучением и переобучением модели (также известный как bias-variance tradeoff).
Проще говоря, чем выше этот коэффициент, тем сильнее учитываются контрольные точки и достигается более гибкая подгонка. Это может привести к переобучению, поскольку модель будет тесно привязываться к обучающим данным и терять способность к обобщению. Снижение этого значения уменьшает гибкость и вызывает противоположную проблему - недообучение.
Модель в таком случае недостаточно «внимательно» следит за обучающими данными и не выявляет основные закономерности. Как правильно подобрать этот параметр - вопрос скорее практический, нежели теоретический, и здесь будем полагаться на эмпирические результаты. Класс Stocker содержит два разных метода для выбора соответствующего значения: визуальный и количественный. Начнем с визуального метода.
# changepoint priors is the list of changepoints to evaluate amazon.changepoint_prior_analysis(changepoint_priors=)

Здесь мы обучаемся на данных за три года, а затем показываем прогноз на шесть следующих месяцев. Сейчас мы не оцениваем прогнозы количественно, а лишь пытаемся понять роль распределения контрольных точек. Этот график отлично демонстрирует проблему недо- и переобучения!
При самом низком значении prior scale (синяя линия) значения недостаточно близко накладывается на обучающие данные (черная линия). Они словно живут своей жизнью, лишь немного приближаясь возрастающему тренду истинных данных. Напротив, самый высокий prior (желтая линия) сильнее приближает модель к учебным наблюдениям . Значение по умолчанию составляет 0.05, которое находится где-то между двумя крайностями.
Обратите внимание также на разницу в неопределенности (закрашенные интервалы) для разных коэффициентов масштаба:
- Самое маленькое из prior дает наибольшую неопределенность в обучающих данных и наименьшую в тестовом наборе.
- Напротив, наивысший prior scale имеет наименьшую неопределенность в тренировочном и наибольшую в тестовом.
Чем выше prior, тем точнее совпадают значения, поскольку он “внимательней” следит за каждым шагом. Однако, когда дело доходит до тестовых данных, модель быстро теряется без привязки к реальным значениям. Поскольку рынок изменчив, нужна более гибкая модель, чем заданная по умолчанию, чтобы она могла обрабатывать как можно больше шаблонов.
Теперь, когда у нас есть представление о влиянии prior, мы можем численно оценить разные значения с помощью набора для обучения и проверки:
Amazon.changepoint_prior_validation(start_date="2016-01-04", end_date="2017-01-03", changepoint_priors=) Validation Range 2016-01-04 to 2017-01-03. cps train_err train_range test_err test_range 0.001 44.507495 152.673436 149.443609 153.341861 0.050 11.207666 35.840138 151.735924 141.033870 0.100 10.717128 34.537544 153.260198 166.390896 0.200 9.653979 31.735506 129.227310 342.205583
Мы должны быть осторожны — данные валидации не должны совпадать с тестовой выборкой. Если бы это было так, мы бы создали модель, лучше «подготовленную» для тестовых данных, что ведет к переобучению и невозможности работать в реальных условиях. В общей сложности, как это обычно делается в , используются три набора: для обучения (2013-2015), для валидации (2016) и тестовый набор (2017).
Мы оценили четыре priors с четырьмя показателями:
- ошибка обучения;
- доверительный интервал при обучении;
- ошибка тестирования;
- доверительный интервал при тестировании, все значения в долларах.
На графике видно, что чем выше prior, тем ниже ошибка обучения и тем ниже неопределенность на данных для обучения. Видно, что повышение уровеня prior снижает ошибку тестирования, подкрепляя интуицию, что близко приближаться к данным — хорошая идея для рынка. В обмен на бóльшую точность в тестовом наборе получаем больший диапазон неопределенности в данных теста с увеличением prior.
Валидационная проверка Stocker выдает два графика, иллюстрирующие эти идеи:


Так как наивысшее значение prior дало самую низкую ошибку тестирования, следует увеличить prior scale еще сильнее, чтобы попытаться улучшить результаты. Поиск можно уточнить, передав дополнительные параметры методу валидации:
# test more changepoint priors on same validation range
amazon.changepoint_prior_validation(start_date="2016-01-04", end_date="2017-01-03", changepoint_priors=)

Ошибка тестового набора сводится к минимуму при prior = 0,5. Установим атрибут объекта Stocker соответствующим образом:
Amazon.changepoint_prior_scale = 0.5
Есть и другие изменяемые настройки модели. Например, паттерны, которые ожидается увидеть, или количество используемых лет в обучающих данных. Поиск наилучшей комбинации требует повторения описанной выше процедуры с несколькими разными значениями. Не стесняйтесь экспериментировать!
Оценка усовершенствованной модели
Теперь, когда наша модель оптимизирована, оценим ее еще раз:
Amazon.evaluate_prediction() Prediction Range: 2017-01-18 to 2018-01-18. Predicted price on 2018-01-17 = $1164.10. Actual price on 2018-01-17 = $1295.00. Average Absolute Error on Training Data = $10.22. Average Absolute Error on Testing Data = $101.19. When the model predicted an increase, the price increased 57.99% of the time. When the model predicted a decrease, the price decreased 46.25% of the time. The actual value was within the 80% confidence interval 95.20% of the time.

Выглядит гораздо лучше! Это показывает важность оптимизации модели. Использование значений по умолчанию дает разумное первое приближение. Но нужно быть уверенным, что используются правильные настройки, так же как мы пытаемся оптимизировать звук стерео, регулируя Balance и Fade (извините за устаревший пример).
«Входим в рынок»
Прогнозирование, безусловно, увлекательное занятие. Но настоящее удовольствие — наблюдать, как эти прогнозы будут отыгрывать на реальном рынке. Используя метод evaluate_prediction, мы можем «играть» на фондовом рынке, используя нашу модель за период оценки. Будем использовать описанную стратегию и сравним с простой стратегией buy and hold в течение всего периода.
Правила нашей стратегии просты:
- Каждый день, когда модель предсказывает рост акций, покупаем акции в начале дня и продаем в конце дня. Когда прогнозируется снижение цены, мы не покупаем акции.
- Если покупаем акции, и цены увеличиваются в течение дня, мы получаем соответствующую прибыль кратно количеству акций, которые у нас есть.
- Если покупаем акции, а цены уменьшаются, мы теряем кратно количеству акций.
Эту стратегию будем применять каждый день на весь период оценки, который в данном случае составляет весь 2017 год. Чтобы играть, нужно передать количество акций в вызов метода. Stocker покажет процесс разыгрывания стратегии в цифрах и графиках:
# Going big amazon.evaluate_prediction(nshares=1000) You played the stock market in AMZN from 2017-01-18 to 2018-01-18 with 1000 shares. When the model predicted an increase, the price increased 57.99% of the time. When the model predicted a decrease, the price decreased 46.25% of the time. The total profit using the Prophet model = $299580.00. The Buy and Hold strategy profit = $487520.00. Thanks for playing the stock market!

Мы получили ценный урок: покупайте и удерживайте! Несмотря на то, что удалось выручить значительную сумму, играя по нашей стратегии, лучше просто инвестировать и держать акции.
Попробуем другие тестовые периоды, чтобы увидеть, есть ли случаи, когда наша модельная стратегия превосходит метод buy and hold. Описанный подход довольно консервативен, потому что мы не играем, когда прогнозируется снижение рынка. Следовательно, когда акции начнут падать, он может работать лучше, чем стратегия buy and hold .

Играйте только на ненастоящих деньгах!
Я знал, что наша модель может это сделать! Тем не менее, она побила рынок только когда у нас была возможность выбрать период тестирования.
Прогнозы на будущее
Теперь, когда у нас есть достойная модель, можно делать предсказания на будущее, используя метод predict_future():
Amazon.predict_future(days=10)
amazon.predict_future(days=100)
 Прогноз на 10 дней
Прогноз на 10 дней
 Прогноз на 100 дней
Прогноз на 100 дней
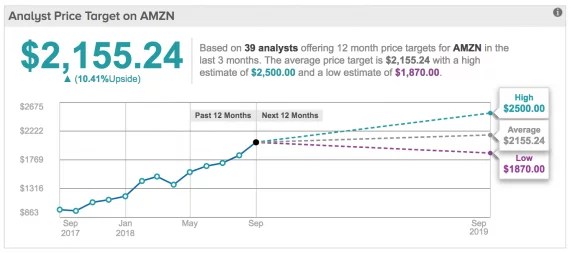 Прогноз популярного сервиса Tipranks.com — найдите 10 отличий от предсказания со Stocker
Прогноз популярного сервиса Tipranks.com — найдите 10 отличий от предсказания со Stocker
Неопределенность увеличивается с течением времени, как и ожидается. В действительности, если бы мы использовали описанный подход для настоящей торговли, мы бы каждый день обучали новую модель и делали прогнозы на срок не более одного дня.
Всем, кто хочет опробовать код, или поэкспериментировать со Stocker, добро пожаловать на GitHub .